



This lockdown period has given people the liberty to explore their talents and likings and we witnessed people pursuing different genre activities ranging from baking cakes to creating content digitally, travelling, painting, starting their own small businesses, etc.
Apart from these people have also shown inclination towards stock market... including me! Believe me, I had no idea about "the market", what is trading and how it is done. Even I dived into trading during this lockdown, since then this is the first thing I do in the morning. :P
Although with time and self learnings I have gained a lot of experience yet sometimes I face problems. One such annoying activity which I usually dislike is keeping track of upcoming IPOs. Yeah right! IPOs. Don't panic with the used jargons, I will explain everything.. just keep reading and stay with me till the end. :)
You must have heard about the launching of famous IPOs like Zomato, Railtel, IRFC, Indigo paints. But these are the ones that created a lot of buzz around the internet. What about others? As of today, there is a total of 35 IPOs have been launched. Crazy right?!!
So, I tried writing a script that keeps track of all the upcoming IPOs using web scraping. I have also documented it and pushed it to my GitHub account. You may easily fork it and play with it. Also, If you like it, do not forget to give a star. Since this is my first blog post on hash node I would really appreciate your valuable feedback that would motivate me to continue.
So let's get started with the post!
Before we dive in let me brief you with topics that we will cover:
1. What is the stock market and IPOs?
2. What is Web Scraping.
3. What is BeautifulSoup.
4. Idea about Tkinter.
What is the Stock Market?
Basically, Stock Markets provide a secure and regulated environment where market participants can transact in shares and other eligible financial instruments with confidence and with zero to low operational risk.
For instance, people go to shopping stores/malls like Walmart for their household grocery supplies.
Such dedicated markets serve as a platform where numerous buyers and sellers meet, interact and transact. Since the number of market participants is huge, one is assured of a fair price. For example, if there is only one seller of a product in the entire city, he will have the liberty to charge any price he pleases as the buyers won’t have anywhere else to go. If the number of sellers for a product is large in a common marketplace, they will have to compete against each other to attract buyers. The buyers will be spoiled for choice with low or optimum pricing making it a fair market with price transparency. Even while shopping online, buyers compare prices offered by different sellers on the same shopping portal or across different portals to get the best deals, forcing the various online sellers to offer the best price.
A stock market is a similar designated market for trading various kinds of securities in a controlled, secure and managed environment. Since the stock market brings together hundreds of thousands of market participants who wish to buy and sell shares, it ensures fair pricing practices and transparency in transactions.

Initial Public Offerings (IPO).
As a primary market, the stock market allows companies to issue and sell their shares to the common public for the first time through the process of initial public offerings (IPO). In layman terms, it essentially means that a company divides itself into a number of shares (say, 20 million shares) and sells a part of those shares (say, 5 million shares) to the common public at a price (say, 50 rs. per share).
I hope now you have a clear understanding of stock markets and IPOs. So without further ado, let's get our business done!
What is Web Scraping?
Let me be very clear right from the beginning, we are in no way trying to scratch the website, we are just trying to extract the relevant information from the website and that's what web scrapping is in simple language!!
According to Wikipedia, Web scraping, web harvesting, or web data extraction is data scraping used for extracting data from websites.
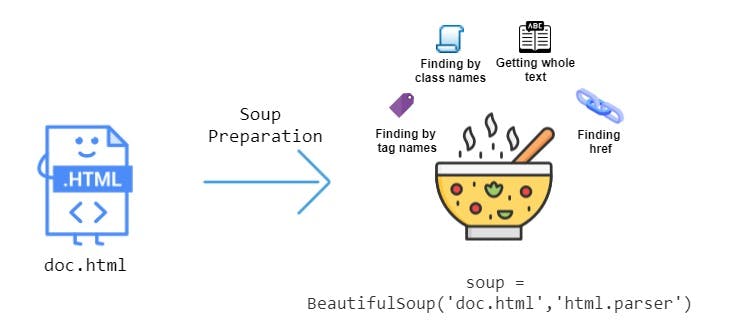
What is BeautifulSoup?
BeautifulSoup is a python library to extract data out of HTML and XML files.
To get BeautifulSoup run pip install bs4 command in the terminal.
What is tkinter?
Tkinter provides Python users with a simple way to create GUI elements using the widgets found in the Tk toolkit.
Okay! so a lot of knowledge transfer(All the IT guys say cheers for 'KT' :P) is done, right? Let's start with coding. Firstly, let's import all the necessary libraries.
import requests
from bs4 import BeautifulSoup
from datetime import datetime
from tkinter import *
Now that we have imported all the relevant libraries let’s decide a website on which we will do web scrapping.
I will be using the very popular and used ‘chittorgarh.com’ . It’s a superb website if you need any information related to IPOs, Brokers, option strategy and much more.. just google ‘chittorgarh.com’ and explore! However, you may use any of your choice.
I hope you have already explored the Chittorgarh site, let’s head to their IPO page and try to fetch all the IPOs that are about to launch. We will store this page link to a variable named url
url='chittorgarh.com/report/mainboard-ipo-list-…
The next step is to make a request to the site and get a response which we will eventually use to fetch information satisfying our requirements.
req = requests.get(url)
Here, the get() method sends a GET request to the specified URL.
If you look closely on-site you will see the data is published on a table. Refer to the following screenshot for a better understanding.
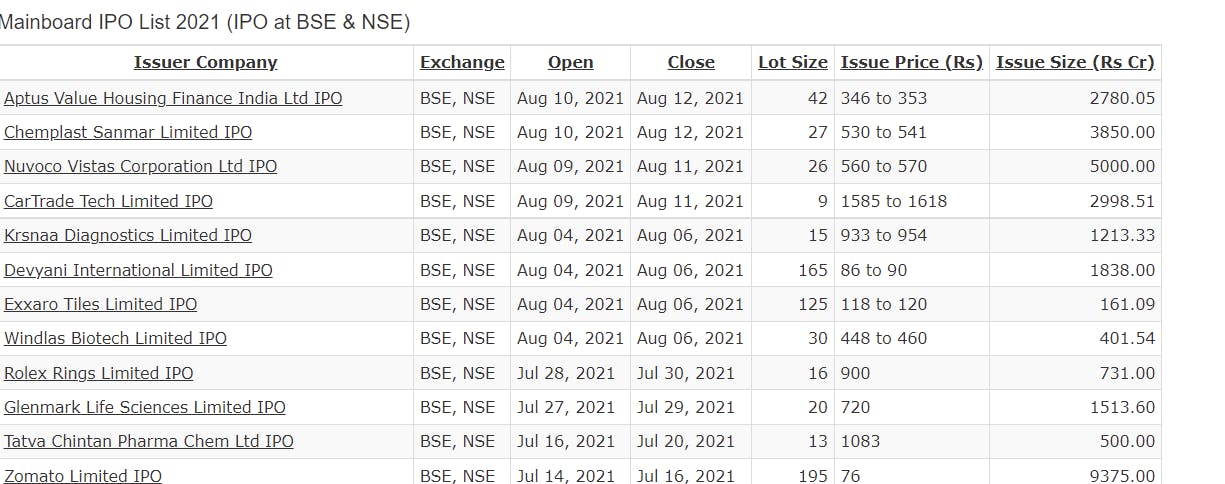
We wish to extract this information which is stored in a table in rows.
As explained earlier, this can be done using the module BeautifulSoup.
content = BeautifulSoup(req.content,"html5lib")
Now we will find tbody in the html content and store it in a variable.
new=[]
tbodyVal= content.find("tbody")
Now that we have tbody value we will fetch IPOs which are usually stored in ‘tr’ tag.
Let’s dive into the actual part of the code:
for row in tbodyVal.find_all("tr"):
rowVal = []
cols = row.find_all("td")
rowVal.append(cols[0].text)
rowVal.append(cols[2].text)
d=cols[2].text
try:
if datetime.strptime(d,'%b %d, %Y')>datetime.now():
new.append(rowVal)
except:
pass
In the IPO table, we are concerned about 2 columns: IssuerCompany and Open. Their place values are 0 and 2 respectively. Also, we are concerned about the IPOs which are yet to launch. So that’s what the above code all does.
Voila! We have successfully scrapped out the list of all IPOs that will launch in near future.
But, wait! This is not it. Let's make our output a Lil catchy using Tkinter.
window = Tk()
window.geometry('450x120')
for i in new:
label = Label(window, text= i[0]+' , '+i[1])
label.pack()
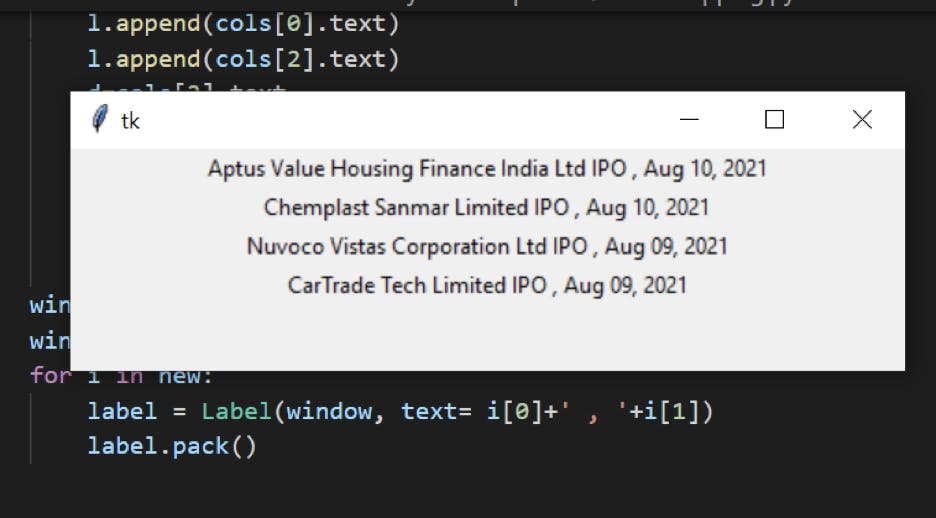
Execute the code and here’s the output window I see on my screen:
Here’s the full code for you to access easily.
import requests
from bs4 import BeautifulSoup
from datetime import datetime
from tkinter import *
url='chittorgarh.com/report/mainboard-ipo-list-…
req = requests.get(url)
content = BeautifulSoup(req.content,"html5lib")
new=[]
tbodyVal = content.find("tbody")
for i in tbodyVal.find_all("tr"):
l = []
cols = i.find_all("td")
l.append(cols[0].text)
l.append(cols[2].text)
d=cols[2].text
try:
if datetime.strptime(d,'%b %d, %Y')>datetime.now():
new.append(l)
except:
pass
window = Tk()
window.geometry('450x120')
for i in new:
label = Label(window, text= i[0]+' , '+i[1])
label.pack()
window.mainloop()