Spark With Python(PySpark)


PySpark is a Spark library written in Python to run Python applications using Apache Spark capabilities, using PySpark we can run applications parallelly on the distributed cluster (multiple nodes). PySpark is a Python API for Apache Spark. Apache Spark is an analytical processing engine for large scale powerful distributed data processing and machine learning applications.
Pyspark Installation
Install Jupyter Notebook. [pip install jupyter notebook]
Install Java 8
To run the PySpark application, you would need Java 8 or a later version hence download the Java version from Oracle and install it on your system.

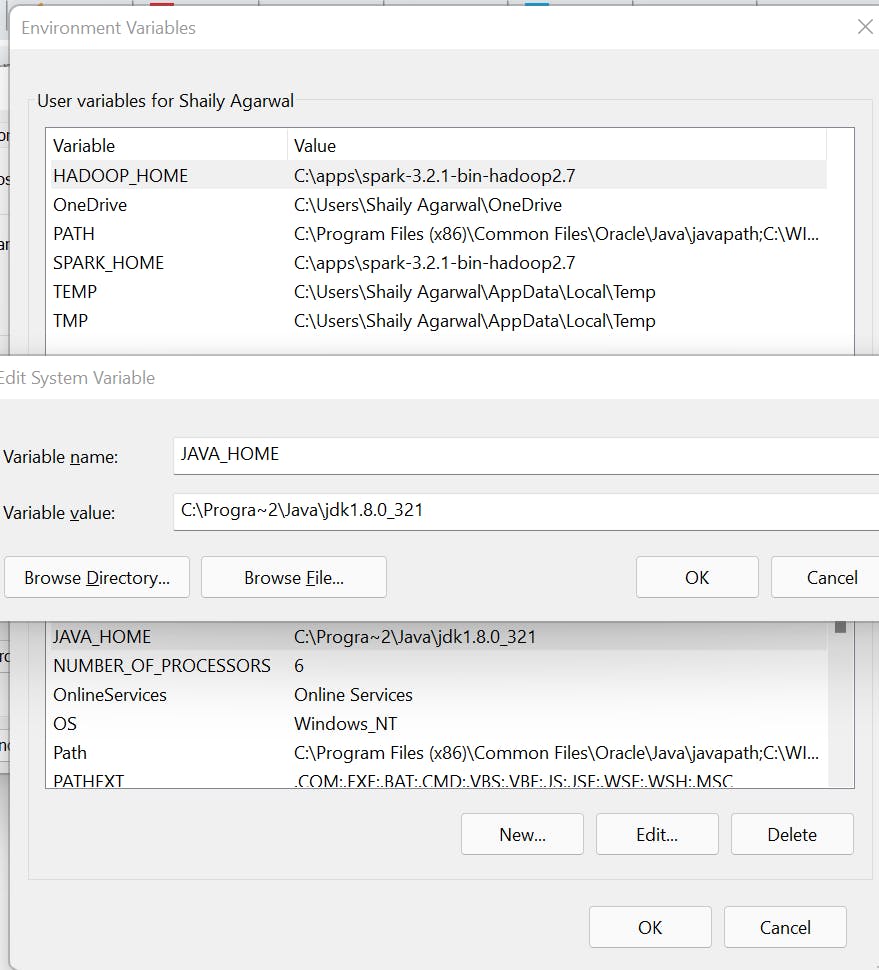
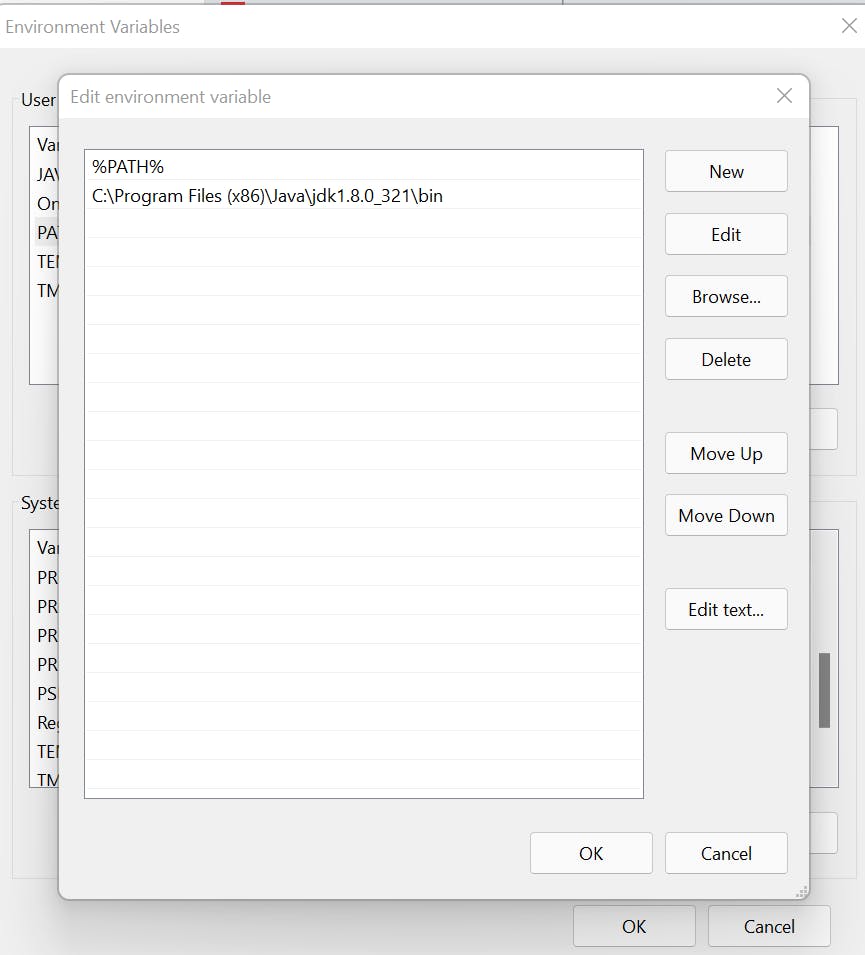
Post-installation, set JAVA_HOME and PATH variable.
Install Apache Spark
Download Apache spark by accessing Spark.
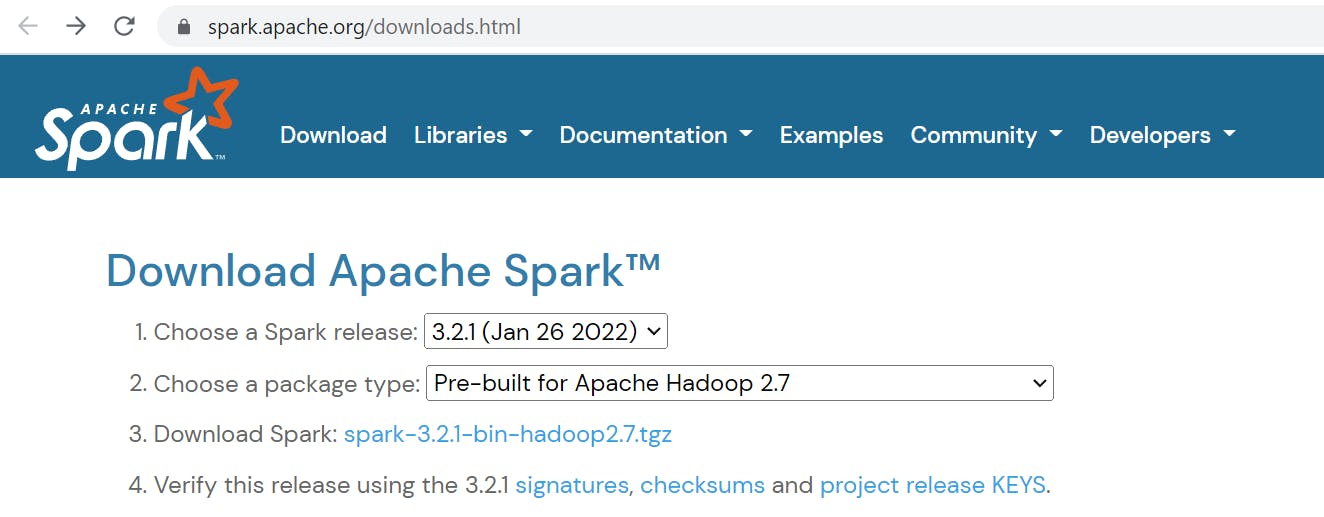
After download, untar the binary using 7zip and copy the underlying folder spark-3.2.1-bin-hadoop2.7 to C:/apps
Setup winutils.exe Download the winutils.exe file from winutils, and copy it to%SPARK_HOME%\binfolder. Winutils are different for each Hadoop version hence download the right version from [github.com/steveloughran/winutils]
PySpark shell Now open the command prompt and type pyspark command to run the Pyspark shell.
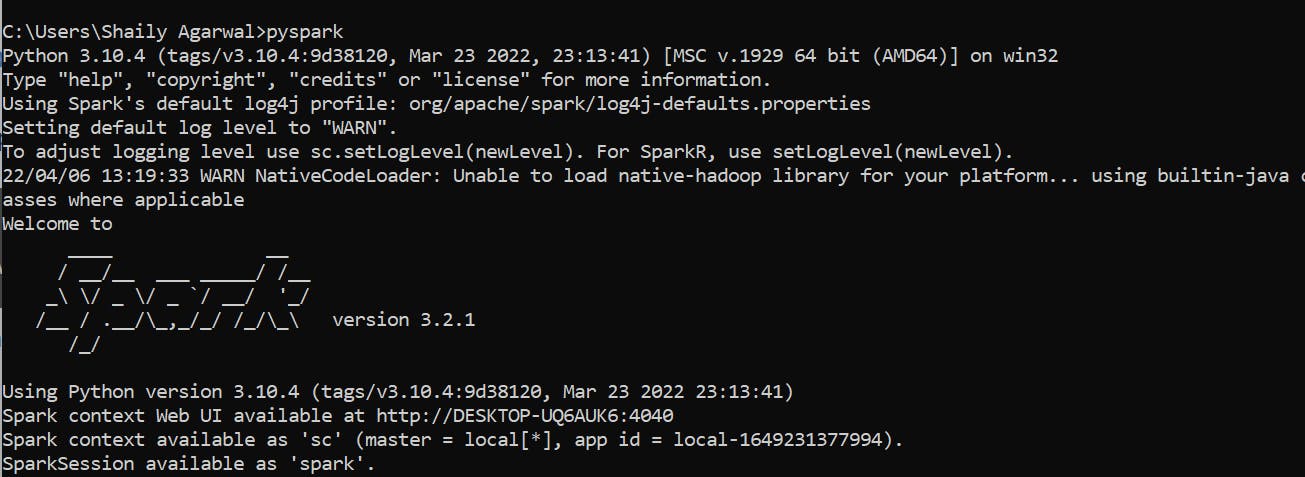
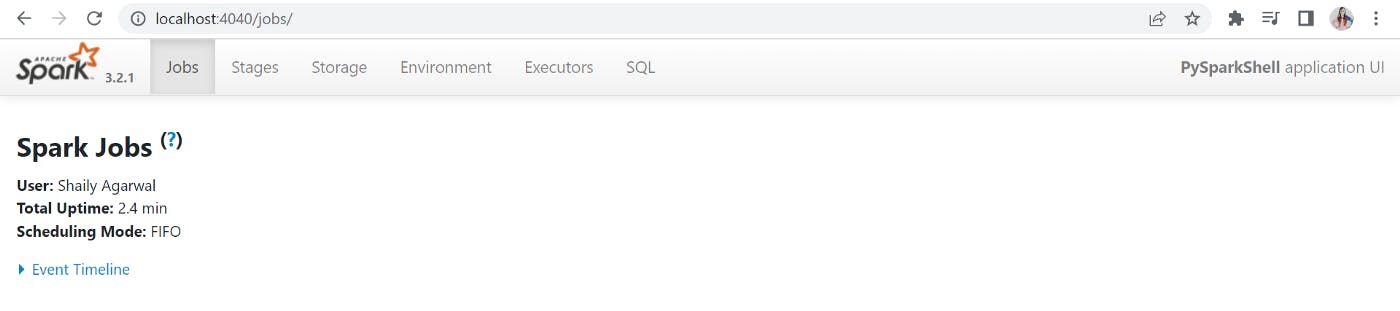
Spark-shell also creates a Spark context web UI and by default, it can access from [localhost:4040].
Jupyter Notebook
To write PySpark applications, you would need an IDE, there are 10’s of IDE to work with and I choose to use Jupyter notebook.
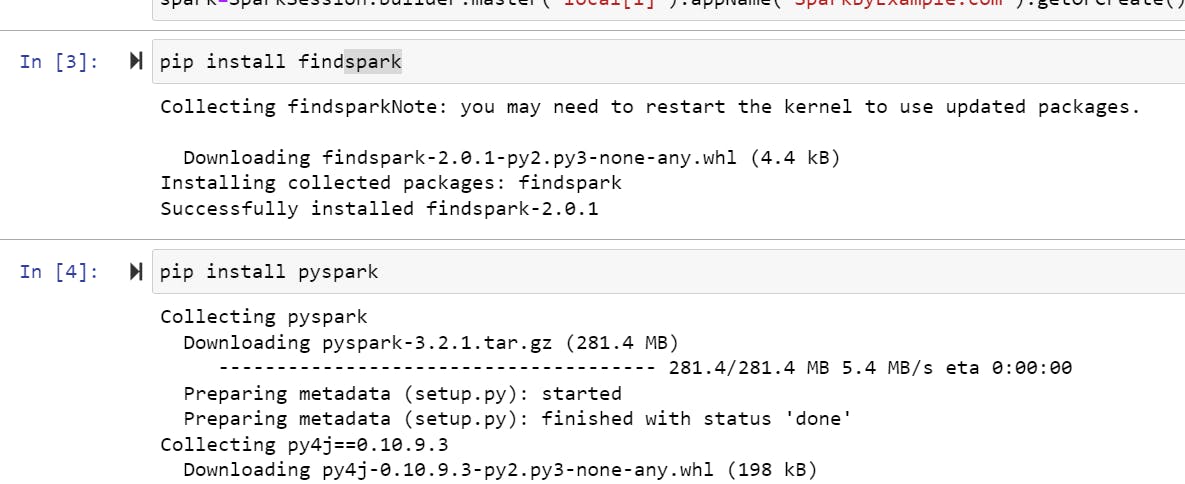
Now, set the following environment variable.
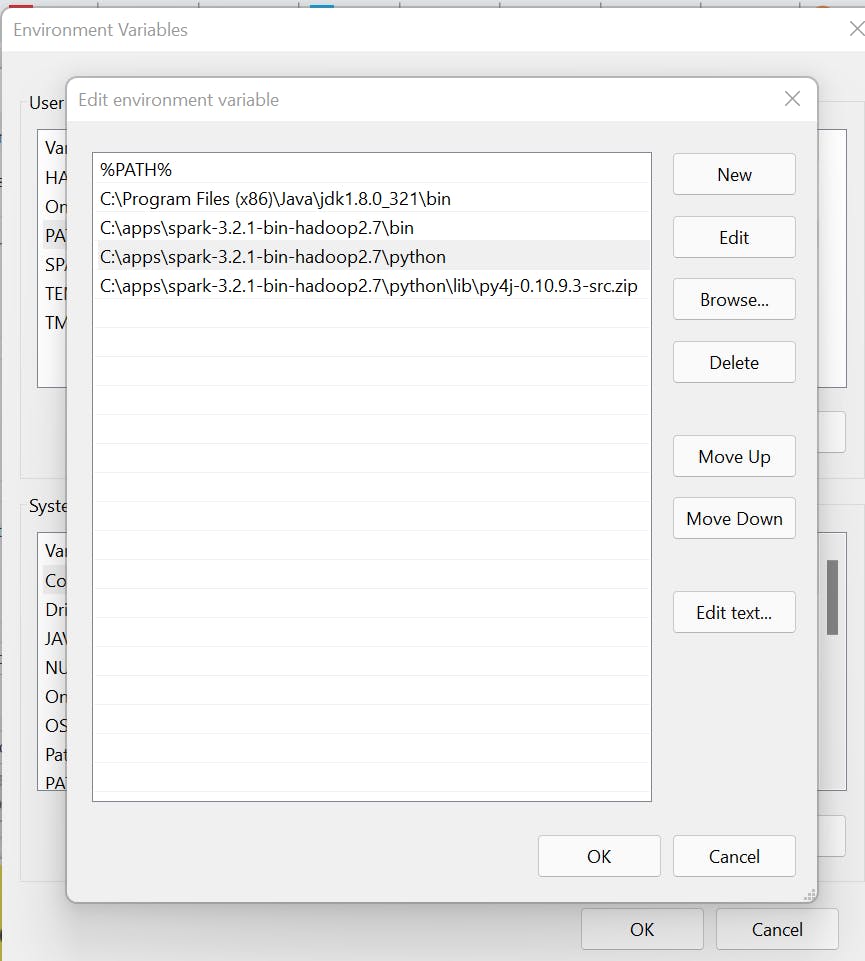
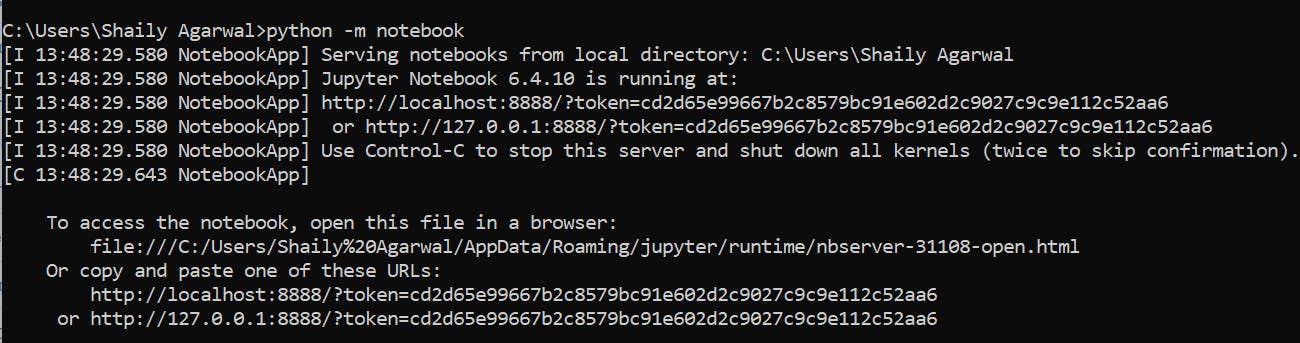
Now let’s start the Jupyter Notebook.
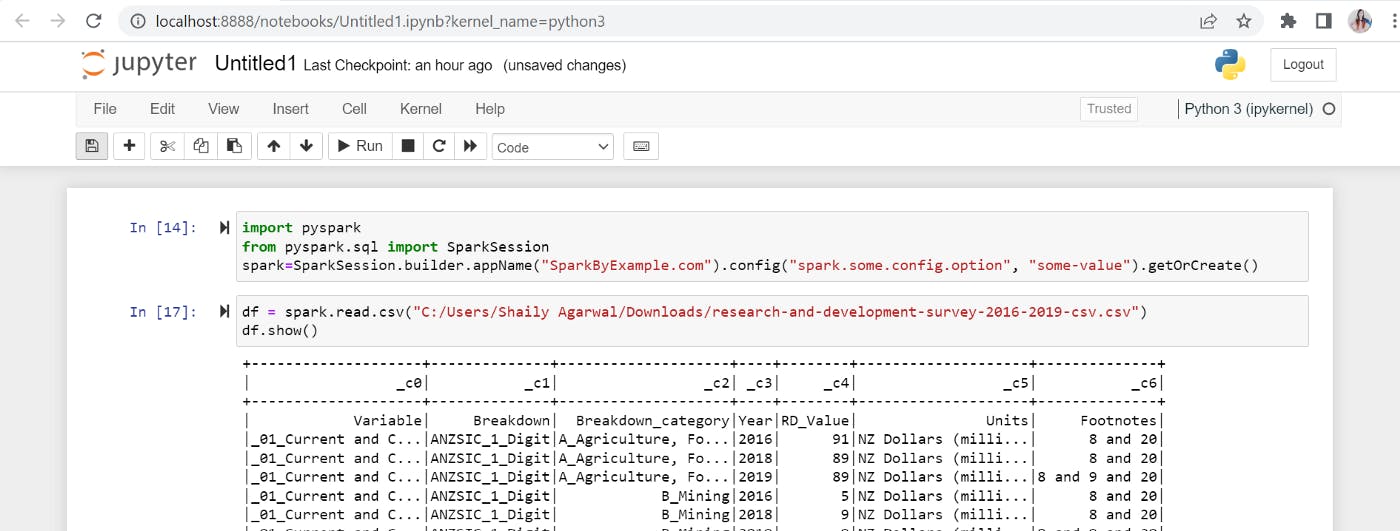
DataFrame from external data sources