



This is an advanced tutorial. If you are just getting started with Cube.js, I recommend checking this tutorial first and then coming back here.
One of the most powerful features of Cube.js is pre-aggregations. Coupled with data schema, it eliminates the need to organize, denormalize, and transform data before using it with Cube.js. The pre-aggregation engine builds a layer of aggregated data in your database during the runtime and maintains it to be up-to-date.
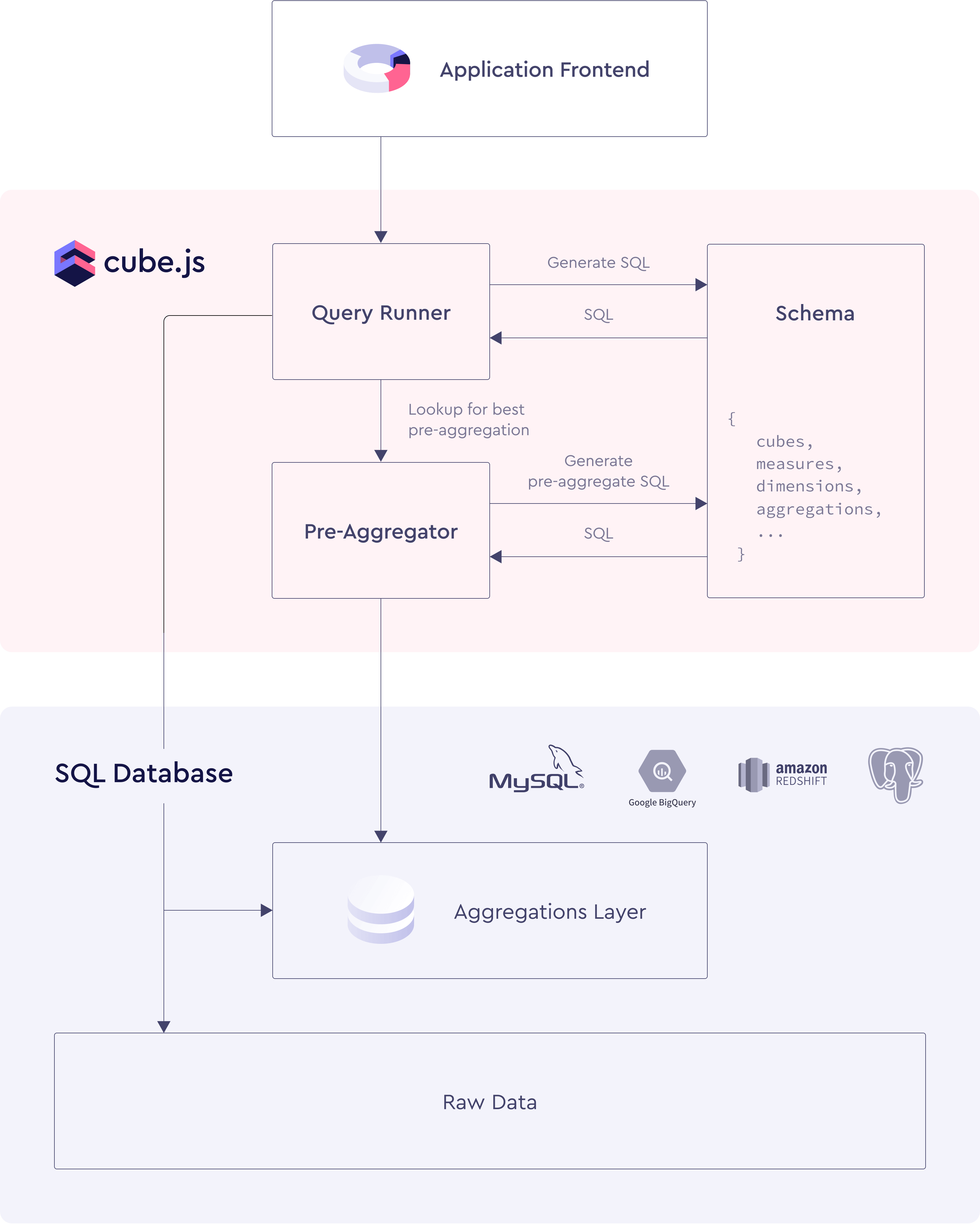
Upon an incoming request, Cube.js will first look for a relevant pre-aggregation. If it cannot find any, it will build a new one. Once the pre-aggregation is built, all the subsequent requests will go to the pre-aggregated layer instead of hitting the raw data. It could speed the response time by hundreds or even thousands of times.
Pre-aggregations are materialized query results persisted as tables. In order to start using pre-aggregations, Cube.js should have write access to the stb_pre_aggregations schema where pre-aggregation tables will be stored.
Cube.js also takes care of keeping the pre-aggregation up-to-date. It performs refresh checks and if it finds that a pre-aggregation is outdated, it schedules a refresh in the background.
Creating a Simple Pre-Aggregation
Let's take a look at the example of how we can use pre-aggregations to improve query performance.
For testing purposes, we will use a Postgres database and will generate around ten million records using the generate_series function.
$ createdb cubejs_test
The following SQL creates a table, orders, and inserts a sample of generated records into it.
CREATE TABLE orders (
id SERIAL PRIMARY KEY,
amount integer,
created_at timestamp without time zone
);
CREATE INDEX orders_created_at_amount ON orders(created_at, amount);
INSERT INTO orders (created_at, amount)
SELECT
created_at,
floor((1000 + 500*random())*log(row_number() over())) as amount
FROM generate_series
( '1997-01-01'::date
, '2017-12-31'::date
, '1 minutes'::interval) created_at
Next, create a new Cube.js application if you don't have any.
$ npm install -g cube.js
$ cubejs create test-app -d postgres
Change the content of .env in the project folder to the following.
CUBEJS_API_SECRET=SECRET
CUBEJS_DB_TYPE=postgres
CUBEJS_DB_NAME=cubejs_test
Finally, generate a schema for the orders table and start the Cube.js server.
$ cubejs generate -t orders
$ npm run dev
Now, we can send a query to Cube.js with the Orders.count measure and Orders.createdAt time dimension with granularity set to month.
curl \
-H "Authorization: EXAMPLE-API-TOKEN" \
-G \
--data-urlencode 'query={
"measures" : ["Orders.amount"],
"timeDimensions":[{
"dimension": "Orders.createdAt",
"granularity": "month",
"dateRange": ["1997-01-01", "2017-01-01"]
}]
}' \
http://localhost:4000/cubejs-api/v1/load
Cube.js will respond with Continue wait, because this query takes more than 5 seconds to process. Let's look at Cube.js logs to see exactly how long it took for our Postgres to execute this query.
Performing query completed:
{
"queueSize":2,
"duration":6514,
"queryKey":[
"
SELECT
date_trunc('month', (orders.created_at::timestamptz at time zone 'UTC')) \"orders.created_at_month\",
sum(orders.amount) \"orders.amount\"
FROM
public.orders AS orders
WHERE (
orders.created_at >= $1::timestamptz
AND orders.created_at <= $2::timestamptz
)
GROUP BY 1
ORDER BY 1 ASC limit 10000
",
[
"2000-01-01T00:00:00Z",
"2017-01-01T23:59:59Z"
],
[]
]
}
It took 6,514 milliseconds (6.5 seconds) for Postgres to execute the above query. Although we have an index on the created_at and amount columns, it doesn't help a lot in this particular case since we're querying almost all the dates we have. The index would help if we query a smaller date range, but still, it would be a matter of seconds, not milliseconds.
We can significantly speed it up by adding a pre-aggregation layer. To do this, add the following preAggregations block to src/Orders.js:
preAggregations: {
amountByCreated: {
type: `rollup`,
measureReferences: [amount],
timeDimensionReference: createdAt,
granularity: `month`
}
}
The block above instructs Cube.js to build and use a rollup type of pre-aggregation when the "Orders.amount" measure and "Orders.createdAt" time dimension (with "month" granularity) are requested together. You can read more about pre-aggregation options in the documentation reference.
Now, once we send the same request, Cube.js will detect the pre-aggregation declaration and will start building it. Once it's built, it will query it and send the result back. All the subsequent queries will go to the pre-aggregation layer.
Here is how querying pre-aggregation looks in the Cube.js logs:
Performing query completed:
{
"queueSize":1,
"duration":5,
"queryKey":[
"
SELECT
\"orders.created_at_month\" \"orders.created_at_month\",
sum(\"orders.amount\") \"orders.amount\"
FROM
stb_pre_aggregations.orders_amount_by_created
WHERE (
\"orders.created_at_month\" >= ($1::timestamptz::timestamptz AT TIME ZONE 'UTC')
AND
\"orders.created_at_month\" <= ($2::timestamptz::timestamptz AT TIME ZONE 'UTC')
)
GROUP BY 1 ORDER BY 1 ASC LIMIT 10000
",
[
"1995-01-01T00:00:00Z",
"2017-01-01T23:59:59Z"
],
[
[
"
CREATE TABLE
stb_pre_aggregations.orders_amount_by_created
AS SELECT
date_trunc('month', (orders.created_at::timestamptz AT TIME ZONE 'UTC')) \"orders.created_at_month\",
sum(orders.amount) \"orders.amount\"
FROM
public.orders AS orders
GROUP BY 1
",
[]
]
]
]
}
As you can see, now it takes only 5 milliseconds (1,300 times faster) to get the same data.
Also, you can note that SQL has been changed and now it queries data from stb_pre_aggregations.orders_amount_by_created, which is the table generated by Cube.js to store pre-aggregation for this query. The second query is a DDL statement for this pre-aggregation table.
Pre-Aggregations Refresh
Cube.js also takes care of keeping pre-aggregations up to date. Every two minutes on a new request Cube.js will initiate the refresh check.
You can set up a custom refresh check strategy by using refreshKey. By default, pre-aggregations are refreshed every hour.
If the result of the refresh check is different from the last one, Cube.js will initiate the rebuild of the pre-aggregation in the background and then hot swap the old one.
Next Steps
This guide is the first step to learning about pre-aggregations and how to start using them in your project. But there is much more you can do with them. You can find the pre-aggregations documentation reference here.
Also, here are some highlights with useful links to help you along the way.
Pre-aggregate queries across multiple cubes
Pre-aggregations work not only for measures and dimensions inside the single cube, but also across multiple joined cubes as well. If you have joined cubes, you can reference measures and dimensions from any part of the join tree. The example below shows how the Users.country dimension can be used with the Orders.count and Orders.revenue measures.
cube(`Orders`, {
sql: `select * from orders`,
joins: {
Users: {
relationship: `belongsTo`,
sql: `${CUBE}.user_id = ${Users}.id`
}
},
// …
preAggregations: {
categoryAndDate: {
type: `rollup`,
measureReferences: [count, revenue],
dimensionReferences: [Users.country],
timeDimensionReference: createdAt,
granularity: `day`
}
}
});
Generate pre-aggregations dynamically
Since pre-aggregations are part of the data schema, which is basically a Javascript code, you can dynamically create all the required pre-aggregations. This guide covers how you can dynamically generate a Cube.js schema.
Time partitioning
You can instruct Cube.js to partition pre-aggregations by time using the partitionGranularity option. Cube.js will generate not a single table for the whole pre-aggregation, but a set of smaller tables. It can reduce the refresh time and cost in the case of BigQuery for example.
Time partitioning documentation reference.
preAggregations: {
categoryAndDate: {
type: `rollup`,
measureReferences: [count],
timeDimensionReference: createdAt,
granularity: `day`,
partitionGranularity: `month`
}
}
Data Cube Lattices
Cube.js can automatically build rollup pre-aggregations without the need to specify which measures and dimensions to use. It learns from query history and selects an optimal set of measures and dimensions for a given query. Under the hood it uses the Data Cube Lattices approach.
It is very useful if you need a lot of pre-aggregations and you don't know ahead of time which ones exactly. Using autoRollup will save you from coding manually all the possible aggregations.
You can find documentation for auto rollup here.
cube(`Orders`, {
sql: `select * from orders`,
preAggregations: {
main: {
type: `autoRollup`
}
}
});