



Many companies are adopting chatbots in context of client service and in-house support. Most of these solutions are connected with some messaging platform like Facebook Messanger, Whats App, Telegram, etc. At the same time, there are great voice assistants (like Alexa, Google assistant, etc.) used privately by non-company users. Not long ago, chatbots were just another interface for some application (mostly web apps), but now they are getting their own identity, humor, knowledge base, personality. They have become more like assistants, instead of question/answer interface, which collect and present data for your system. Voice interface is more natural to human than, any visual solution. Does this mean that standard websites will no longer be used? No. In most cases, chatbots and web pages will complement each other and in more complex situation, you will reuse your chatbot in your web application, what will improve user experience. Additionally, more and more attention is devoted to accessibility, which resulted in new trends in user experience. Voice interfaces are part of this movement.
It is not easy to create good chatbot. Creating good voice assistant is even harder, but the real challenge is to integrate it with the web application. There are a lot of things which you need to do. First, your app needs to listen to the user, what can be achieved with < audio > and getUserMedia() or other audio API available in browsers. When audio will be caught, stream it to back-end. You can do it with websocket and node.js. Back-end need to create chunks of audio, based on what users says, but before that, you need to separate background noise from valuable parts of recording. When you get specific part of recording, you need to use speech recognition software to get transcript of what user said. There are ready to use libraries or services for it. When you will have text, use NLP to understand transcript. Again, there are lot of libraries and services for that. At the end, when you know what user said, select correct action and pass parameters supplied by user. Now you can use some basic code to get data, make calculation etc. When you are done, send data to front-end and make changes in visualization. Also, voice assistant should say something, so you use speech synthesis.
Most of this require a lot of custom code. Sure, you can do large part of software in front-end and simplify it a little, but it requires a lot of hardware resources. Also, if you use some services for speech recognition and NLP, you do not want to make your private keys and passwords available for anyone. This is why you send users audio to your back-end and make requests to services there.
There is a lot of things to cover, a lot of things to learn. How to start? How you can jump right in the topic without reading a lot of resources and writing a lot of code? Is it possible to test some of this technology with small effort? Is it possible to create proof of concept, to interest investors or your boss? Web Speech API to the rescue!
Let’s start with something simple. I want to create a simple assistant, which will help me in presentation for my speech. During talk I like to walk and make gestures. To switch between slides and code, or to change slides, I need to get back to a computer and make few clicks. This makes me uncomfortable. I want to be close to my computer only when I code live and free when I talk. Let’s make a voice assistant, which will do all of this stuff for us. We will use: Web Speech API to receive voice commands and to make assistant talk; Dialogflow for NLP and reveal.js for presentation.
In this example, we will create a simple presentation and the voice assistant will just switch slides. It will teach you basics to make more sophisticated solutions. Please keep in mind that, I want to present couple of technologies, not to teach you how make your app safe and how to configure server correctly. I will help you to start your journey in voice applications land and grasp general concept of such applications. During production of the app you should include some additional things like:
- put many things in some config file or read it from database
- handle errors and exceptions
- communication with dialogflow on your back-end
- make all credential safe
We will put most of logic in front-end. Code will be custom-made, based on my Chrome settings, you might need to change it a little bit to make it work with your browser. I use newest version of Chrome on desktop, but on Firefox not all functions worked as supposed.
First, we will build simple presentation with reveal.js. It will contain few slides with some dummy text. We start from running vagrant box with ubuntu 16 and apache. Project folder is mapped into /var/www, which will be root folder for application. Now we must add some vhost and ssl, which will be needed later. To make it as simple as possible, log into vagrant box and create key with certificate placed in /home/vagrant directory:
> openssl genrsa -out slides.key 2048
> openssl req -new -x509 -key slides.key -out slides.cert -days 3650 -subj /CN=slides
We go to /etc/apache2/sites-available and create configuration for virtual host. Again, to make it fast, we use defaults — copy one of default config and change it. We will use slides as an url to our application:
<VirtualHost *:443>
SSLEngine on
ServerName slides
SSLCertificateFile /home/vagrant/slides.cert
SSLCertificateKeyFile /home/vagrant/slides.key
ServerAdmin webmaster@localhost
DocumentRoot /var/www/public
<Directory /var/www/public>
Options Indexes FollowSymlinks MultiViews
AllowOverride All
Order allow,deny
allow from all
</Directory>
</VirtualHost>
Now we create public folder in our root, where we add index.html with random text. This way, we can make sure that everything works as expected. We also need to enable site, add ssl module to apache and restart it. It required a few more commands:
sudo a2ensite *
sudo a2enmod ssl
sudo service apache2 restart
Last thing is to add virtual host on host machine. I use Windows, so I go to C:\Windows\System32\drivers\etc\hosts and add line with IP of my virtual machine and slides domain. Now on Chrome, when we will open slides, we see dummy page from /var/www/public on virtual machine. Server is ready, now let’s write some code.
In public folder, we add folders (css, js, lib, plugin) from github.com/hakimel/reveal.js. In public/lib/js/, we add jsrsasign-all-min.js from github.com/kjur/jsrsasign and few empty files in public/js/ folder: google_token.js, slides.js, voice.js. We change index.html to:
<!DOCTYPE html>
<html class="sl-root decks export loaded ua-phantomjs reveal-viewport theme-font-montserrat theme-color-white-blue">
<head>
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
<title>deck: Slides</title>
<meta name="description" content="Slides">
<link rel="stylesheet" href="/css/reveal.css">
<link rel="stylesheet" href="/css/theme/white.css">
</head>
<body>
<div class="reveal">
<div class="slides">
<section>Some first slide</section>
<section>Single Horizontal Slide</section>
<section>
<section>Vertical Slide 1</section>
<section>Vertical Slide 2</section>
</section>
</div>
</div>
<script src="lib/js/jsrsasign.min.js"></script>
<script src="js/google_token.js"></script>
<script src="js/reveal.js"></script>
<script src="js/slides.js"></script>
<script src="js/voice.js"></script>
</body>
</html>
In public/js/slides.js, we initialize reveal.js slide engine:
Reveal.initialize({
controls: true,
controlsLayout: 'edges',
progress: true,
transition: 'convex',
backgroundTransition: 'convex',
history: true
});
In Chrome, we go to slides. When we open the page for the first time, Chrome will inform us about certificate problems, but we are going to accept the risk and open the page. After that, we should see first slide and switch between them manually. If you followed me to this point, we can say basic setup is done, so let’s get to voice recognition.
Before we move on, we need to plug in microphone into computer. When we are ready, let’s change public/js/voice.js file. First, we create voice recognition object and set it to operate continuously. It will catch voice and try to match it with patterns. If we would not do set it to operate continuously, it would turn off after first match. Additionally we set language to en-US :
var SpeechRecognition = SpeechRecognition || webkitSpeechRecognition;
var speechRecognizer = new SpeechRecognition();
speechRecognizer.continuous = true;
speechRecognizer.lang = "en-US";
Our listener is ready to activate, so we write function to make it active:
function startListener() {
speechRecognizer.start();
}
Now our app will listen, but would not do anything with that what it heard. We need to define what to do when something happens. We can achieve this by setting callbacks for SpeechRecognition events. First, we want to log all start/stop events. We want to restart listener on stop event. You may ask “why to restart it if we set speech recognition to work continuously?” and that would be a good question. You see, in this case “continuously” means “do not stop after first recognized sentence, just listen as long as you can and when you catch something, throw it into event”. After some time, Chrome just shut down listener and your speech recognition will stop to work. Also, if some error happen, speech recognition is turned off and in that case, we also want to turn it on again. Here is code:
speechRecognizer.onaudiostart = function(event) {
console.log('onaudiostart');
};
speechRecognizer.onaudioend = function(event) {
console.log('onaudioend');
};
speechRecognizer.onend = function(event) {
console.log('onend');
speechRecognizer.start();
};
speechRecognizer.onnomatch = function(event) {
console.log('onnomatch');
};
speechRecognizer.onsoundstart = function(event) {
console.log('onsoundstart');
};
speechRecognizer.onsoundend = function(event) {
console.log('onsoundend');
};
speechRecognizer.onspeechstart = function(event) {
console.log('onspeechstart');
};
speechRecognizer.onspeechend = function(event) {
console.log('onspeechend');
speechRecognizer.stop();
};
speechRecognizer.onerror = function(event){
console.log(event)
};
We need to do something with caught sounds and recognized speech. We will listen to onresult event, which is fired when SpeechRecognizer create transcript. Here is something important — speech recognition constantly changes results during parsing your voice. You will get access to results before process will finish to build final transcript. We need to check results and only if it is final, we will use it. Transcript is simple text, so we can operate on it as on text input. We will log all caught responses and if it matches our action, we will run it. Remember that we are operating on string, so any whitespaces, char size (lowercase/uppercase) will change it to something different. We create such code:
speechRecognizer.onresult = event => {
for(var i=event.resultIndex; i<event.results.length; i++){
var transcript = event.results[i][0].transcript;
if(event.results[i].isFinal){
transcript = transcript.trim().toLowerCase();
console.log(transcript);
switch (transcript) {
case "right":
Reveal.right();
break;
case "left":
Reveal.left();
break;
case "down":
Reveal.down();
break;
case "up":
Reveal.up();
break;
}
}
};
};
Now we can run a little test — we open slides. In Chrome we see, that in navbar (close to my url) some icon showed up, which indicate, that web app tries to get access to microphone and as user I need to set permissions for web page. I can set permissions only for specific url and if my app is served through https, I can set it permanently. If it is not secured with ssl, app will require acceptance each time it ask for access to microphone. We set up vhosts and added ssl, so we can set it once and forget it. After all settings are done, we refresh the page and start to give voice commands through microphone. If you followed me and created all required code, you should be able to change slides with simple words like “right”, “left”, “down”, “up”. If there are some problems, open console to see if any warnings or errors were caught and try to say command a little slower or louder. Do not give few commands to fast, because system will create one transcript, which represent sentence composed of a several words. If parsing takes too long, try to play a little with microphone’s settings and try to reduce background noise.
We made it… but something is wrong. We can say “right”, “left”, “down”, “up” and it will switch slides, but we want to say “change slide to next” or maybe “next slide” or anything else. With current solution we would need to write all options in switch… What if my speech recognition would create wrong transcript ex. “app” instead of “up”? I am not native English speaker and speech recognition is not perfect too. Trying to cover all possible cases I would end up with thousands of lines of code. I need a real chat bot solution.
Let’s move on and add some NLP. I mentioned to put your NLP on back-end, but here we will connect with dialogflow on front-end. First, we need to configure an agent in dialogflow. We open dialogflow.com, sign in with our google account and we create new agent. In it we create new entity “slide” with 4 entries. Each entry has some value (something like id) and synonyms (additional pointer for specific entry). It looks like that:
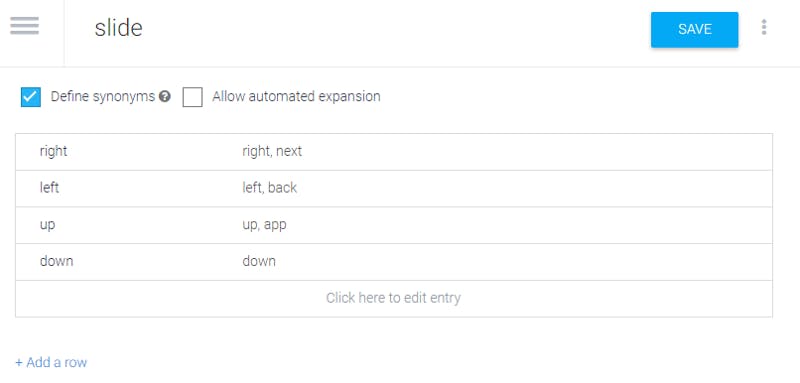
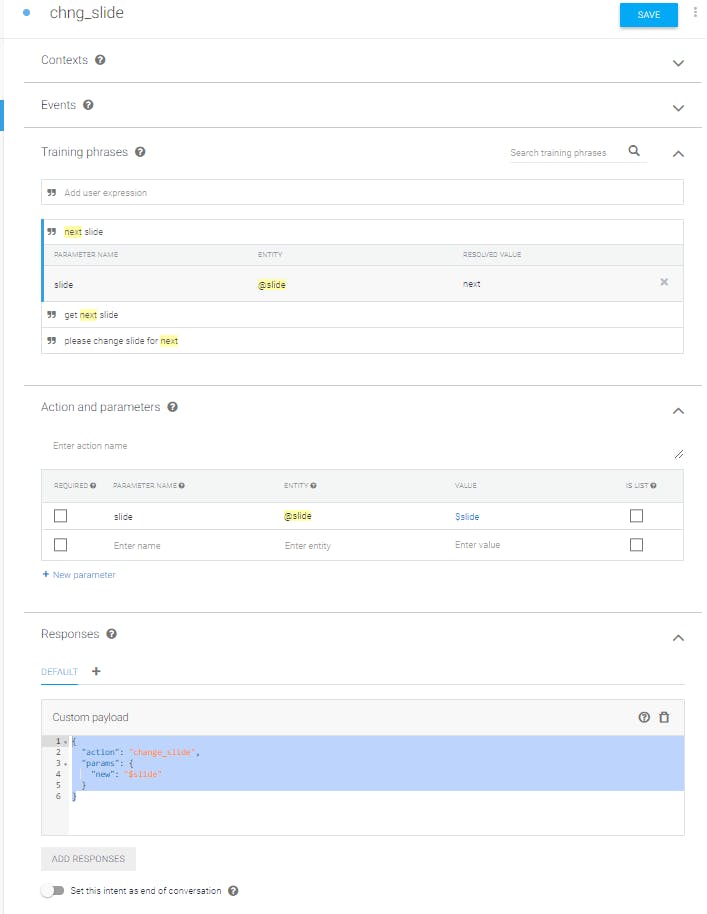
Now we need intent, which represent dialog option. For that, we add new intent chng_slide. We add three training phrases “next slide”, “get next slide”, “please change slide for next” and we connect word “next” with entity “slide” (when you select part of text, pop-up will be displayed with option to select entity). We remove text payload and add custom payload with json (use “Add responses” button and select “Custom payload”):
{
"action": "change_slide",
"params": {
"new": "$slide"
}
}
Our custom payload will be sent as response on API call. Training phrases will be used as text examples for texts comparator. Connection between text and entity informs NLP processor which part of our example is dynamic and can be used as parameters to define entity. Configuration looks like that:
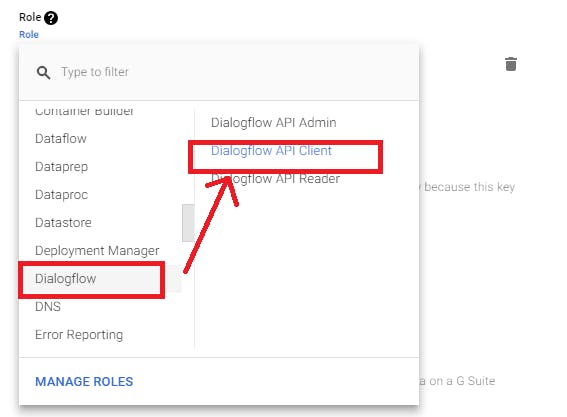
Now our bot is configured and we need to connect it with front-end. For that, we need to get access to dialogflow REST API, which use OAuth. Let’s get through this together. First we need to create Service Account with access to our bot from google cloud service. In dialogflow in agent configuration options, in “Google project” section, we have “Project Id” and “Service Account” — note it somewhere, we’ll need that later.

Service Account is linked to google project settings — open it. In new window with google cloud platform administration (page which opens from “Service Account” link), we need to add new service account. For that, we need to set role: dialogflow client. We can find dialogflow on left column and select client on right column, or just start to type “dialogflow API client”.
On bottom, there are two checkboxes, select first with option to share new private key and select JSON as key type.
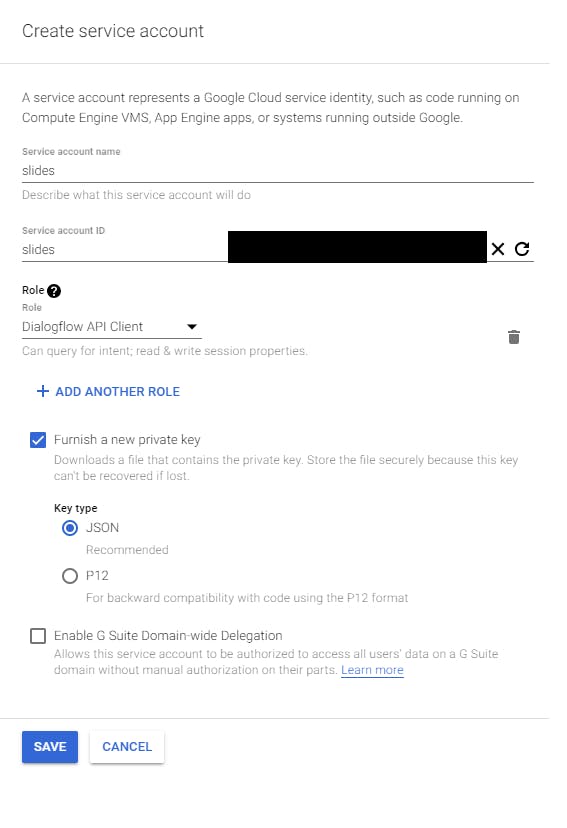
When we save it, we will also get json file with data to access our service. Let’s assume that our json look like this:
{
"type": "service_account",
"project_id": "my_project_id",
"private_key_id": "some_long_private_key",
"private_key": "-----BEGIN PRIVATE KEY-----\nLOTOFCHARINHERE==\n-----END PRIVATE KEY-----\n",
"client_email": "slides@my_project_id.iam.gserviceaccount.com",
"client_id": "my_client_id",
"auth_uri": "accounts.google.com/o/oauth2/auth",
"token_uri": "accounts.google.com/o/oauth2/token",
"auth_provider_x509_cert_url": "googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "googleapis.com/robot/v1/metadata/x509/slid…"
}
Now we get back to our code. To communicate with REST API, we need OAuth token, what we can achieve by making request to googleapis.com/oauth2/v4/token and add JWT token. For JWT token we use data from JSON file, which we get when we created Service Account in google cloud platform. Received OAuth token will be stored globally. This is not safe approach and do not use it on production.
All code required to receive token will be kept in public/js/google_token.js. First, we create JWT token with jsrsasign 8.0.12. Based on code, which I presented for JSON key, our js should look like that:
const unix = Math.round(+new Date()/1000);
const privatekey = "-----BEGIN PRIVATE KEY-----\nLOTOFCHARINHERE==\n-----END PRIVATE KEY-----\n";
const jwtHeader = {
alg: "RS256",
typ: "JWT"
};
const jwtPayload = {
iss: "slides@my_project_id.iam.gserviceaccount.com",
scope:"googleapis.com/auth/cloud-platform",
sub: "slides@my_project_id.iam.gserviceaccount.com",
aud: "googleapis.com/oauth2/v4/token",
iat: unix,
exp: unix + 3600
};
const jwtToken = KJUR.jws.JWS.sign('RS256',jwtHeader, jwtPayload, privatekey);
Now we create post data and send it with request to google API. In global variable we save OAuth token, which we get from response. We start to listen to user voice, after dialogflow token is received. This way, we make sure, that we do not make any call to dialogflow without Oauth token. This is our code:
var gapiToken = 0;
var tokenRequestBody = "grant_type=urn:ietf:params:oauth:grant-type:jwt-bearer&assertion="+jwtToken;
fetch('googleapis.com/oauth2/v4/token', {
method: 'POST',
body: tokenRequestBody,
headers: {
'content-type': 'application/x-www-form-urlencoded'
}
})
.then(response => response.json())
.then(jsonData => {gapiToken=jsonData.access_token; startListener()})
.catch(err => {});
Nice, we can communicate with API. So let’s change our code in public/js/voice.js starting from onresult action:
speechRecognizer.onresult = event => {
for (var i = event.resultIndex; i < event.results.length; i++) {
var transcript = event.results[i][0].transcript;
if (event.results[i].isFinal) {
transcript = transcript.trim().toLowerCase();
analizeData(transcript);
}
}
};
In function analizaData, we make call to dialogflow API. We need to send request to specific url, which include project id and session id: dialogflow.googleapis.com/v2/projects/your…. Project id can be taken from dialogflow project settings (you remember that we note it few minutes ago). Session is session id, created by us and it must be individual for each our client, because dialogflow keep in session data like context. For testing purpose we will hardcode session id:
function analizeData(text) {
console.log(text)
let query = {
"queryInput": {
"text": {
"text": text,
"languageCode": "en-US"
}
}
};
fetch('dialogflow.googleapis.com/v2/projects/my_p…, {
method: 'POST',
body: JSON.stringify(query),
headers: {
'content-type': 'application/json',
'Authorization': 'Bearer ' + gapiToken
}
}).then(response => response.json()).then(serveResponse);
}
Response from dialogflow must be parsed. Based on in it, we will make some action in application. We are interested in custom payloads, which contains action name and its parameters. We use action as function name and params as arguments (again when you work on production application be sure to check response, validate it and parse it properly):
function serveResponse(data) {
data.queryResult.fulfillmentMessages.forEach(fullfilment => {
if (fullfilment.payload != undefined){
window[fullfilment.payload.action](fullfilment.payload.params);
}
});
}
function change_slide(params) {
Reveal[params.new]();
}
Now when you test it, it still work, but you can use more phrases to activate action. Also when you log in to dialogflow, check training section. There you will find all incoming messages and you can use them to “teach” your bot. You can assign new phrases to existing intents and create new intents to do more or react properly on incoming messages.
There is one more thing, which we want to add. As you remember, we want to create assistant which does not just follow your order, it also talks to you. We would not do any fancy thing now — we’ll just add voice to our application. Any time response from dialogflow will contain text payload, we want to hear it.
First, we need to initialize speech synthesis and create text to be read. To do that, we change a little serveResponse function:
function serveResponse(data) {
data.queryResult.fulfillmentMessages.forEach(fullfilment => {
if(fullfilment.text != undefined) {
fullfilment.text.text.forEach(text => {
let utterThis = new SpeechSynthesisUtterance(text);
utterThis.voice = voice;
speechSynthesis.speak(utterThis);
})
}
if (fullfilment.payload != undefined){
window[fullfilment.payload.action](fullfilment.payload.params);
}
});
}
Now each time we get text, it is read. I’m using Windows, so when I test speech synthesis, I get default system voice in my locals. I want to use English voice, which sounds more naturally. First I need to know what I can use, for that I log all available voices, which I get with speechSynthesis.getVoices(). When I know what voices I have, I can test them and select one… I suggest you do the same.
I selected ‘Google UK English Female’. We know that available options will not change now, so we can hardcode its name. At the top of ourpublic/js/voice.js we add few lines:
var voice = undefined;
var voices = undefined;
function getVoices() {
if (typeof speechSynthesis === 'undefined') {
return;
}
voices = speechSynthesis.getVoices();
if(voices.length > 0) {
selectVoice('Google UK English Female');
}
}
function selectVoice(name) {
for (i = 0; i < voices.length; i++) {
if (voices[i].name === name) {
voice = voices[i];
}
}
}
getVoices();
if (typeof speechSynthesis !== 'undefined' && speechSynthesis.onvoiceschanged !== undefined) {
speechSynthesis.onvoiceschanged = getVoices;
}
Nice. Now we can chat with our presentation. We can easily add more functionality served by assistant — we just need to add new methods in js and create more intents in dialogflow. Also we can teach our bot to recognize new phrases, without changing code of our application.
What’s next? You can start from moving your communication with NLP into back-end, cleaning code, adding error handling. Next, you can add more actions like: change background, start/stop, fullscreen, read slide text.
When you will finish playing with the app, you can think about more useful projects. Of course you need to remember, that this solution is limited to specific webbrowser and specific languages (for now). It is not very fast and have some problems with recognizing speech, but it is enough to create prototype and to present your idea to clients. With good developer team you can create your own solution for voice application. To make your app available for other browsers, you will need stream audio to back-end and parse it there.
I hope this article was useful and helped you start your journey with web voice application. I hope that you will test other possibilities and follow your ideas to create interesting solutions, which will make Internet more interactive and also that your work will inspire others.
As an additon, let’s get through some example to describe when we can use such solution.
Olga is owner of online clothes shop, which has a lot of followers on Facebook. She added chatbot for Facebook Messanger, which offer few functionality: suggestion of some clothes and creation of full stylization based on communication with the client (chat bot stylist), option to make orders or check order’s status. When her shop had became popular, she created online changing room based on WebAR, with virtual stylist, which has been based on voice recognition and chat bot. Now users can open her web page and activate change room app, in which they are able to talk with virtual stylist and try some clothes or even full stylizations, which can be ordered later with simple voice order.
Let’s think about other use case, for example Bob’s construction company, which builds prize-winning buildings. Some time ago, Bob created dedicated web application for his team, which is based on WebVR, WebAR and speech recognition. With help of WebGL module, architect can create projects, which is used by marketing team during presentation with WebVR module. Also construction team uses WebAR module to compare reality with plans and locate walls, doors, electricity, etc. The appliaction has standard inputs and speech recognition interface, which made virtual assistans possible to implement. System change project based on voice commands supplied by architect. It is also used during presnatation in front of investors, when presenter is changing lights, furniture, wall decoration etc. only by asking assistant to do it. Construction team does not need any fancy remote-controled devices or joysticks to operate AR, they just talk with assistant like “where window should be”, “what kind of wall should stand here”, “where should I put cable” etc.
Think about car workshop, owned by Luis. He created fancy web app with AR, image recognition and voice assistant. He looks under hood, pulls some old cable, but he’s not sure where to connect it. He can ask “Where this cable should be connected?” and his assistant gives him instructions, while app visualize where the cable should be connected.
Let me present one last example — city guide page, which has voice support for disabled and blind people. Speech recognition and bot are responsible for navigate through the page based on voice commands, while Speech Synthesis presents page’s content to user.