



The most alluring part in machine learning and Artificial inteligence is, that it gives us possibility to start rethinking about everything, by using them - you can see everything from completely different point of view and I think, sometimes this fact of 'rethinking' is the key for new inventions.
I had such kind of moment few days ago, it was really interesting and I decided to write about this experiment.
I created my twitter account approximately 7 years ago, but I hadn't used it very often and after few months, I connected it with one of my websites and installed 'auto-retweet' bot on it. After this, lots of things had changed, I didn't have time for my website, I removed this bot and as I am not really fond of social networks - my twitter account had been paused for a few years.
Several months ago, I decided to start using Twitter. I wanted to share my publications, my public repos (or maybe not only mine) - with the other people, so this is how I decided to rejoin Twitter, but of course I had the followers with absolutely different interests based on my account's past activity. So, to be honest -it affected on my motivation really badly.
I decided to find such kind of users - for whom I would be interesting too.
At first, When you start activity on Twitter and you don't have lots of posts ( of course I deleted older posts :D ) and followers - the chance is big, that the persons you follow - won't follow you back and you need to add really interesting posts for a long time to represent yourself as best as possible.
We have mentioned 'adding followers', so before I start writing about the main parts of this story, I want to share Twitter's rules and limitations, because penalties on Twitter for unethical actions are very serious.
Here are some important links:
So, our goal is to make classification model based on Twitter's users' data (we will generate it later), to predict users' actions in the future - will this user follow us or not, when we send him/her following request. So, to simplify - it should help us to find people - who will follow us in future.
At first, I needed Python package, because communicating straight with Twitter api - isn't a good idea and it needs much more time, so as we know Python is 'batteries included' and I found a great package very easily, which has all the functionality, that I needed for this project and what's more important - it has great documentation as well.
Here is the link:
For using this package, first we need to install it using pip.
$ pip install python-twitter
And after this, we need api credentials from Twitter, you can get it from here very easily:
If it seems little bit confusing, you can see detailed instruction with screenshots: %[python-twitter.readthedocs.io/en/latest/ge…]
Okay, now we can connect successfully with Twitter api:
Now it's time to start data mining. We need to collect enough data, to train our model and here are two options how to get it : first, which is harder and which I did because I didn't have any choice - we should try to follow interesting people and save whether they follow us or not and the second option -for those, who already has enough amount of friends and followers - you can use this data to train your model.
In my case, the second option wouldn't work and I had to choose the harder one. So, for the first scenario I needed to find popular people on Twitter, who were mostly posting about programming/machine learning, because their followers would be also very good for me, so I started collecting data about those kind of users.
First, I choose 'a Twitter rockstar' user, who always posts about programming or ml and next get the list of his/her followers:
After that, I try to get detailed information about each of them. The package, I'm using, returns me this kind of data for each user :
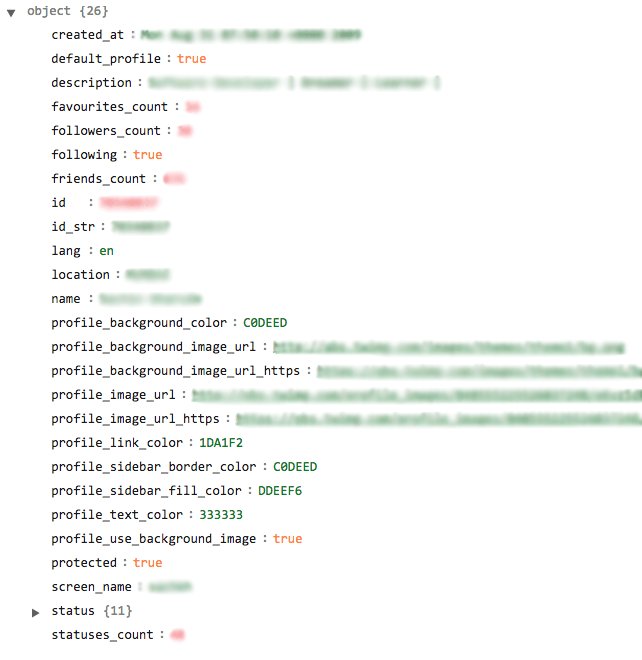
Here is really interesting information, which I can use for training my model, but I don't want to follow each of them, I want to follow only those people, who has the same interests as me and who has some activities(see line 28).
In spite of the fact, that both Twitter api and our package give us possibility to follow users very easily:
Still, you have to be careful, so that your actions won't look like a spam or not to break Twitter rules.
So, as you can see, I am using simple 'if condition' to filter people, who are not active or who don't have enough amount of friends. Because I want to save maximally filtered data.
I decided to save information about users in relational database and I am using Sqlite as database, because it's absolutely enough for us and I didn't want to waste time for such kind of things. Also, in application side I use only sqlite3 package to connect database, without any orm, I wanted it to be as simple as possible.
For the second scenario, we are using almost the same code, but instead of getting data from other users' followers- we are getting data about our followers and followings and save all of this information in our table.
First, we get info about our followers and followings :
And finally, we save everything into our table, as it was in previous example.
So, I already have the information, that I needed.
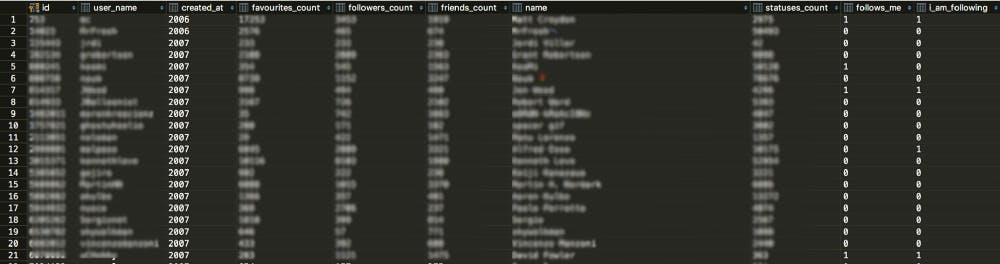
I want to start training my model and for this, I need to choose features for it. We have already seen how does the result look like, which we have from Twitter api. I decided to use only few of them for training my model : created_at , favourites_count, friends_count, friends_count, statuses_count.
Although, I was not satisfied by training process and I think it's very easy to guess why: It's hard to guess if a user still actively uses Twitter account only based on this data, maybe he/she has lots of posts, but all of them are posted 1 year ago, so Idecided to remove column created_at and statuses_count from features' list and instead of it, add information about the last posting date. You can get information about it like this :
I decided to convert this string into integer format and save how many days have gone after last tweet from this user. I wrote a small function for it:
And I can already use this function in my main loop :
It's not an easy job to collect data for your model, it needs minimum few days and sometimes more than weeks, so during those days - a lot of things had been changing with users, whose data have we already saved in our db, so i wrote codes for making my data always up-to-date(for examle: friends list, followers list, etc…) and I can run these codes before I start creating my model.
finally, my data looks like this :

I don't know which ide or editor do you use, I almost always choose Intellij products, in this case Iam using Pycharm. I am using same ide also for connecting with sqlitedb and it gives us possibility to convert our data into csv format very easily.
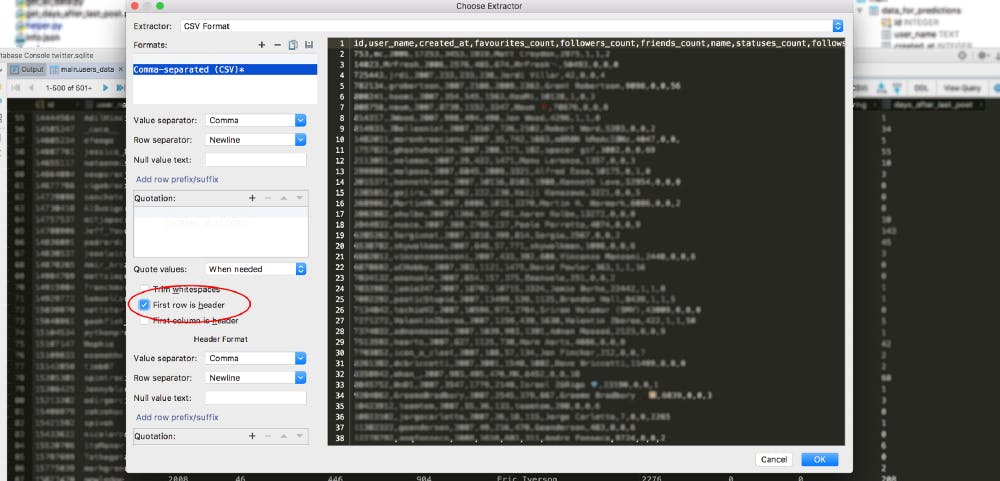
I check that I want header as a first row.
Train, Evaluate, Predict
And now the most interesting part. For our last step, we can use Google Colab, which I think is one of the most useful Google products. First, I am importing necessary packages.
Next, we need to upload our csv file and it's really easy when you use Colab, you just need 2 lines of code and next, authentication code.
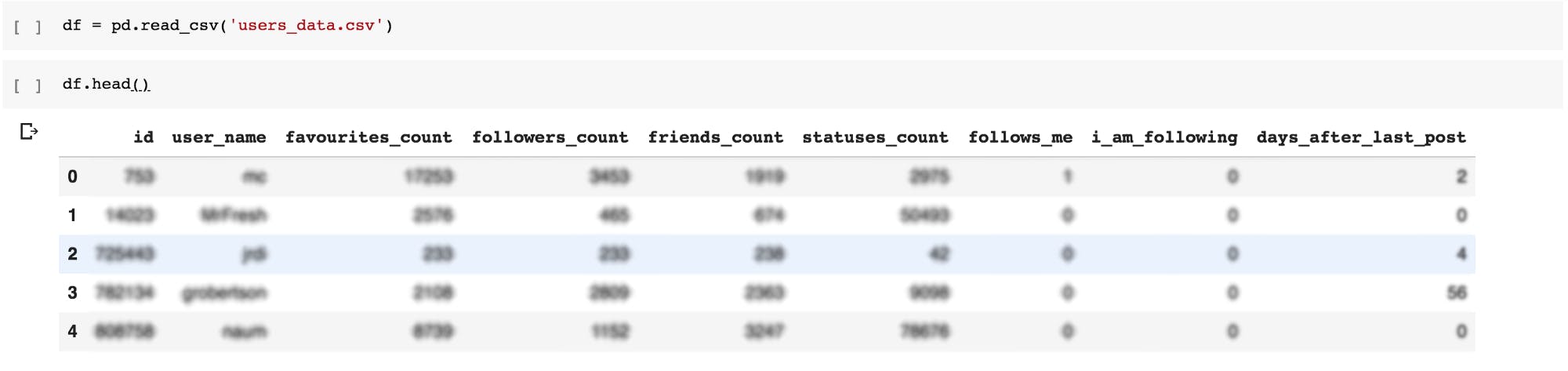
After we upload our file, we can open it using Panda and see how it looks like.
Maybe you already know, that in Twitter there exist private accounts, which means, that you cannot see users' posts, before they give permission for that. So, in such situations you can not see user's last post. In my opinion, feature days_after_last_post is really important and I decided not to use users for training, who don't give information about this data. We can add this filter in sql like this :
select ud.* from users_data ud where ud.days_after_last_post is not null;
Or you can filter it right here, in Colab.
We can also see how many followers do we have using panda:
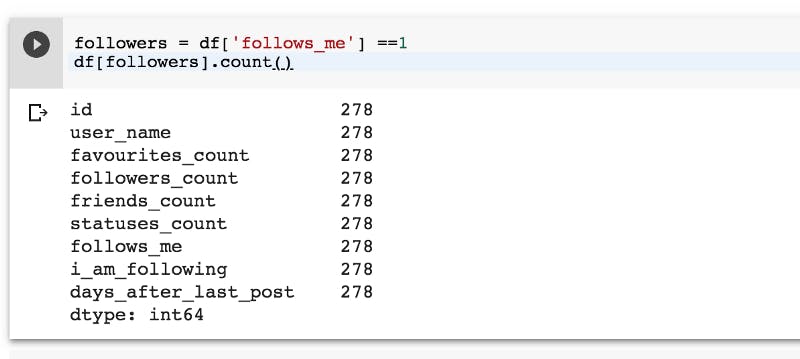
Now we can create variables for our features and for label:
When we already have our features and the target, we will use Scikit-learn to split the data for convinience. Scikit-learn has a train_test_split function for splitting a Panda's DataFrame into a training and testing set.
We are giving the target and features as a parameter to train_test_split function and it returns randomly shuffled data. We have 30% of data for a test set and 70% for training set.
Now, I will call function numeric_column for each feature, because luckily all of my features are numeric. Next, I will create list for the feature columns,
And now we can create list for feature columns.
Input Function, testing and evaluation
We need to have input function, which must return a tuple, containing two elements : features and list of labels and we use this input function for our model, because when we train it - we have to pass the features and the labels to the model.
But, of course, it's not mandatory to write it by our hand, there is already function for it with the name 'pandas_input_fn' and we will use it :
And now it's time to instantiate Model
We are ready to train our model :
We trained it and now, we are able to evaluate our model. For evaluating, we pass eval_fn as a parameter to evaluat function :
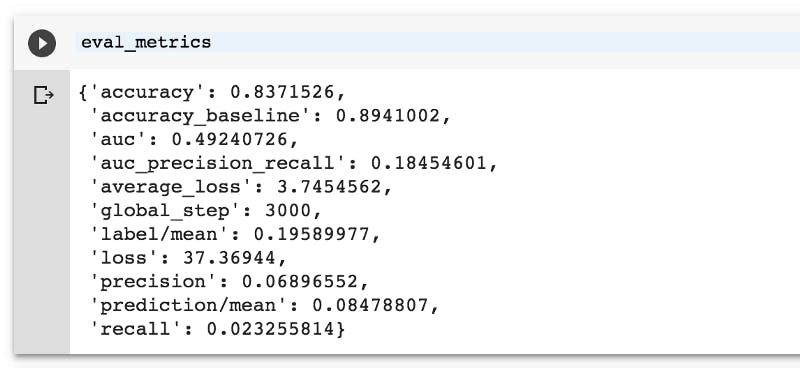
You can see on the screen, that in my case, accuracy was 80%+, which, I think, for this kind of data is normal - I only had info about 1400 users and only had 4 features. Peoples' decisions sometimes don't depend on these features, so our accuracy is satisfying for me right now. Now I can use this model to make prediction on real data.
Prediction
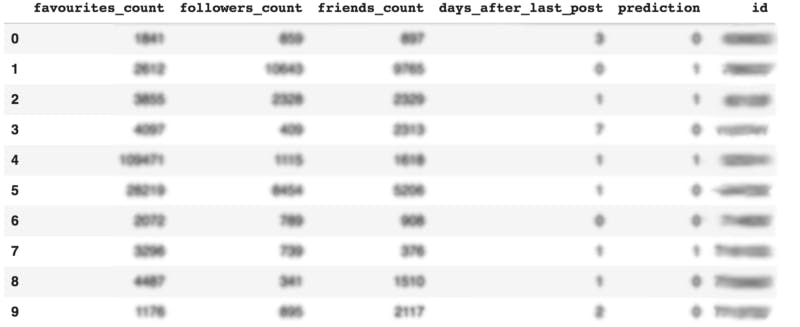
Finally, we can get the list of those users, who will answer back on our friend request depending on our model's prediction.
Of course, you can train your model better to get much more accuracy, you can use different features or change whatever you want, because this experiment is just for fun and for spending more time with Tensorflow and other libraries.
Thank you for taking the time to read this story :)