



Hi there! My name is Jaden, and I'm a frontend developer and a content specialist here at Fauna. But that's my day job; by night, I'm Batman.

Just kidding, I'm an amateur linguist. That'd be awesome if I was Batman though.
Maybe I'm not quite stopping crime, but I'd love to give you a sneak peek into my nerdy hobby! One thing I love doing is creating constructed languages! This is actually pretty common; conlangs — as they're known — are invented for international communication (like Esperanto), for science fiction (like Klingon), for education or research (like Lojban), to affect change in the thinking of its speakers (like Toki Pona), to discover the limits of human expression (like Ithkuil), or for a smattering of other purposes.
It takes a lot to invent a conlang, but its quite a rewarding process. The problem is, there aren't many management tools out there that can keep up with the complexity of a spoken language. After all, it's too complicated to fit neatly into a spreadsheet-style database.

This type of app involves complexity that only Fauna can handle! So in this article, I'm going to show you what I did about the lack of good software in the conlanging space and how Fauna made this all possible. As for a preview, here are a few features I'll demonstrate through this project:
- How to use Fauna's multi-tenancy efficiently
- How to run GraphQL from serverless functions
- How to make the best use of NoSQL
- How to store vector images without any friction
- How to change "columns" of a "table" from "row" to "row"
- How to get the most of Fauna's built-in temporality
- How to scale a database automatically
That's a lot of stuff to demo! Let's hop to it.
Our first collection
So first, we've got to create a collection to store basic information about all of the languages built in the app. Here's what we've got to store:
- The name of the language — every good conlang has a name that perfectly captures what it's about. Note that this will not be unique.
- A key — this key will give us scoped access to the child databases and also serve as our login credential. The users can store this in their password manager.
- The creator's name — somebody needs the credit!
- The creator's email — this will help us further identify creators.
This is actually super easy to create! I just signed up for a new account at fauna.com and it brought me here:
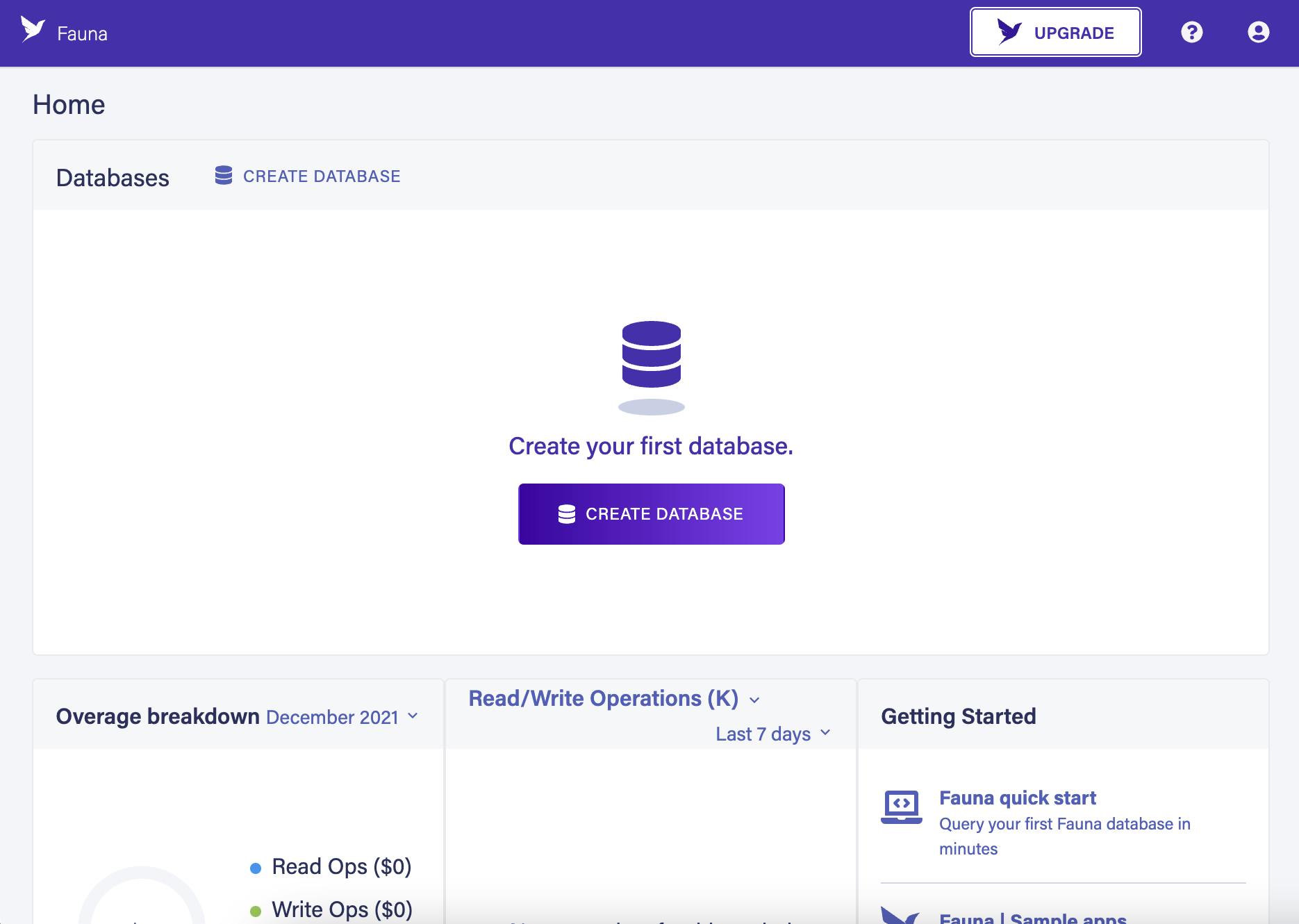
Click the Create Database button, if you're following along, and set the name to languages and the region group to whatever you want. I chose United States because the rates are lower and I'm not too concerned about the latency.
Inside there, press the New Collection button and call it Language. In that collection, we’re going to keep some metadata about the account associated with the language we’re editing.
Next, we’re going to write the code to work with documents inside our new collection in a Netlify function. I quickly spun up a repo, ran npm install uuid node-fetch faunadb to give us access to the Fauna JavaScript driver and a couple other things, and made this functions/language/language.js file:
const { Client, query: q } = require('faunadb');
import 'node-fetch' as fetch;
const fs = require('fs');
import { v4 as uuidv4 } from 'uuid';
const createLanguage = async ({ name, creatorName, creatorEmail }) => {}
exports.handler = async ev =>
ev.httpMethod != "POST"
? { statusCode: 404 }
: {
statusCode: 200,
body: await createLanguage(JSON.parse(ev.body))
};
To get us started, here’s what creating a document in that collection looks like in Fauna.
const createLanguage = async ({ name, creatorName, creatorEmail }) => {
const parentClient = new Client({
secret: process.env.FAUNA_ADMIN_KEY
});
// we're not going to let the client see the admin key though
// so right here, we're going to make a scoped public key just for them
// more on that in a minute
await parentClient.query(
q.Create(
q.Collection('Language'),
{
data: {
dbName: 'the_randomly_generated_name_of_the_right_child_db',
key: 'our_scoped_client_key',
name: 'language name',
creatorName: 'person name',
creatorEmail: 'creator@example.com'
}
}
)
);
}
Making a child database for each language
While most traditional databases would tell you it’s ridiculous to make a completely new database for each user of your application, that isn’t the case in Fauna. It’s so easy and manageable to create new child databases and organize them as you’d like that this multi-tenancy actually becomes an extremely useful paradigm for modeling our data.
What we’re going to do for our conlang manager app here is create a brand new database for each language. The key we’re storing in the parent Language collection is going to give the client access to do a few things inside this child database directly via GraphQL. That means that our createLanguage function from just a little bit ago is actually going to be composed of a few steps:
- Create the child database and an admin key for it so we can do some administrative operations.
- Import a schema for our child database so that the client can easily consume it via GraphQL.
- Create a role on the child database that limits the scope of what the client can do. We don’t want them making any big changes, we just want them to be able to read and modify their data.
- Get a key that’s associated with that confined role.
- Add a document to the parent
Languagecollection with the name of our language, the creator’s info, the name of our child database, and the special key from step 5 (psst... we just did this part!)
If this sounds a smidgeon confusing, don’t worry. It did at first for me as well. But it will start to get a little bit more intuitive over time, especially if you’re coming from more traditional databases where this paradigm was impractical. Let’s dive in!
Step 1 is spinning up our child database. Where we have a comment right now in languages.js, we’re going to add this:
const dbName = uuidv4();
await parentClient.query(
q.CreateDatabase({ name: dbName })
);
const adminChildKey = (
await parentClient.query(
q.CreateKey({
database: q.Database(dbName),
role: 'admin'
})
)
).secret;
The first chunk creates our child database and the second chunk creates an admin key for it.
Step 2 is generating and importing a schema for each of our child databases. Here’s one that’ll work for us:
type Phoneme {
manner: String
place: String
roundedness: String
height: String
phonation: String
notes: String
ipa: String
symbols: [Symbol] @relation
}
type Symbol {
svg: String
phonemes: [Phoneme] @relation
}
type PhonotacticRule {
allowed: Boolean!
construction: String!
}
type Conjugation {
name: String!
rootWord: Word!
conjugatedWord: String
}
type Word {
root: String!
partOfSpeech: String!
conjugations: [Conjugation]
}
type Metadata {
sentenceStructure: [String]!
syllableStructure: [String]!
}
type Note {
note: String
}
type Query {
phonemes: [Phoneme]
symbols: [Symbol]
phonotacticRules: [PhonotacticRule]
conjugations: [Conjugation]
words: [Word]
metadata: Metadata
notes: [Note]
}
You might’ve noticed a couple odd things in here. Let me go through them quickly, because each of these collections might demonstrate a different concept in Fauna worth exploring.
First, the only required field on the Phoneme collection is id, and that’s intentional. A “phoneme” is just a sound you can make with your mouth, but believe it or not, that’s a pretty arbitrary category. Sounds come in the form of vowels — which are described by the place the sound is made, the height the sound is made at, and the roundedness of your lips, as well as any special phonation styles, like using a creaky voice — and also in the form of consonants — which also have place and phonation attributes, but care more about the manner in which you produce the sound, like a snap for a /t/ and the exhale of an /h/. I know that’s a lot, but basically, it means that each document in this collection (or in SQL terms, each “row” of this “table”) is going to have different attributes depending on the sound we’re describing! I could’ve gotten around this predicament by creating a collection for the vowels and one for the consonants, but it would’ve made it really tough to model the Symbol collection, so this is our best bet. You’ll see that it’s actually not as confusing as I’ve made it here, as in practice, we get to just describe the sound however is most appropriate without worrying about GraphQL yelling at us.
Secondly, we have a many-to-many relationship between Symbols and Phonemes. When Fauna makes collections for all of these types, it’ll make a special one called phoneme_symbols to keep track of this relationship outside of their respective collections:
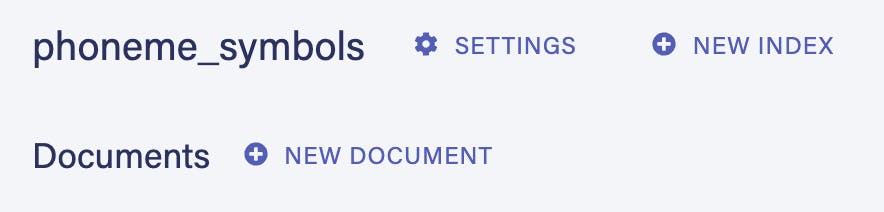
Thank goodness, because this would be a pain to model ourselves.
💡 Thirdly, a quick linguistics lesson: Technically, only verbs (action words) can be conjugated. That’s what happens when a verb changes based on factors around it, like how in most dialects of English, you can say “I go, you go, we go”, but not “he go”. The conjugation of “go” for the third-person singular (another single person or object, like he or it) is “goes” — we must say “he goes”. This gets really complex in a lot of languages, hence us creating a whole collection for it. Nouns (people, places, things, and abstract ideas) are declined instead of conjugated, but for the sake of consistency and simplicity we’re just going to use the word “conjugate” in our GraphQL schema.Fourth, we don’t have a single query to fetch all of our data. That would require explicitly defining a new type called allData or something like that and defining its relationship to all of our other types, which seems very inelegant and confusing. For right now, if we need more than one piece of data at a time, we can just run the queries side by side.
Fifth, the Metadata collection is going to only have one document in it. The reason we’re doing it like this and not by just putting these fields on the parent database collection is so that we can access it all in one GraphQL request. We’d have to send another request with a new API key in the header as those two pieces of data would be in a different database altogether than most of our language’s data. Therefore, we’ve created a singular-document collection specifically for this purpose. Here’s what we’re storing:
- General sentence structure — this is the general order of the words in a sentence. It's very important to have this chosen, but it's actually a lot more complicated than this, so we're going to let the user type out whatever extra rules they'll create in the notes field.
Syllable structure — this is the order of the consonants and vowels that are allowed in a word. This is going to be an array of syllable structure options.
💡 Another quick linguistics lesson incoming: Each syllable can be made of a vowel sound, plus a beginning consonant (the onset) and/or a final consonant (the coda). In English, we allow groups of consonants in certain patterns in those places, but every language allows different patterns. Take a syllable like "train", where the onset is actually both "t" and "r". English speakers can manage to say as one sound. In contrast, Hawaiian doesn't allow that, so a native Hawaiian speaker likely would have trouble pronouncing "train". That's part of the reason why "Merry Christmas" becomes "Mele Kalikimaka" in Hawaiian — they insert vowels between all their consonants because their language demands they do. Other languages allow more complex combinations: for example, the Serbs in Bosnia call their country "Srpska". That’s five consonants in a row! If you're curious, here's a set of slides that explains the concept in more detail.
Perfect! Let’s stick all that in step 2 in the JS, so now it looks like this:
// add GraphQL schema to child database
await fetch(`graphql.us.fauna.com/graphql`, {
method: "post",
body: `
type Phoneme {
manner: String
place: String
roundedness: String
height: String
phonation: String
notes: String
ipa: String
symbols: [Symbol] @relation
}
type Symbol {
svg: String
phonemes: [Phoneme] @relation
}
type PhonotacticRule {
allowed: Boolean!
construction: String!
}
type Conjugation {
name: String!
rootWord: Word!
conjugatedWord: String
}
type Word {
root: String!
partOfSpeech: String!
conjugations: [Conjugation]
meaning: String!
}
type Metadata {
sentenceStructure: [String]!
syllableStructure: [String]!
}
type Note {
note: String
}
type Query {
phonemes: [Phoneme]
symbols: [Symbol]
phonotacticRules: [PhonotacticRule]
conjugations: [Conjugation]
words: [Word]
metadata: Metadata
notes: [Note]
}
`,
headers: {
"Authorization": "Bearer " + adminChildKey
}
});
Great! We’re coming along nicely. Step 3 is creating a role specifically for the child database so that we can do CRUD operations from the client side without giving people who steal this public API key the ability to do anything more nefarious.
// step 3
// get reference to child db client
const childClient = new Client({
secret: adminChildKey,
domain: "db.us.fauna.com"
});
// create a role with specific privileges
await childClient.query(
q.CreateRole({
name: 'public',
privileges: [
// here we'll map through some collections and indexes
// and give them the correct permissions
...([
'Phoneme',
'Symbol',
'PhonotacticRule',
'Conjugation',
'Word',
'Metadata',
'Note',
// fauna made this extra collection because we have a
// many-to-many relationship between phonemes and symbols
'phoneme_symbols'
].map(collection => ({
resource: q.Collection(collection),
actions: {
'read': true,
'write': true,
'create': true,
'update': true,
'delete': true
}
}))),
...([
'phonemes',
'metadata',
'words',
'conjugations',
'symbols',
'phoneme_symbols_by_phoneme',
'phonotacticRules',
'phoneme_symbols_by_symbol',
'notes',
'phoneme_symbols_by_phoneme_and_symbol'
].map(index => ({
resource: q.Index(index),
actions: {
'read': true
}
})))
]
})
);
Step 4 is creating a new key that belongs to that role. It’s similar to step 1, just for our new child database.
const publicChildKey = (
await childClient.query(
q.CreateKey({
role: q.Role('public')
})
)
).secret;
Step 5 is adding the document to the original parent collection, including our new user key. We did this at the end of the last section, but for review, here’s the code with our new public key and the proper input information:
// create document in parent collection
await parentClient.query(
q.Create(
q.Collection('Language'),
{
data: {
dbName,
key: publicChildKey,
name,
creatorName,
creatorEmail
}
}
)
);
And then to finish, we’ll just return JSON.stringify({ key: publicChildKey }); and call it a day. Now, when we post to this serverless function, it’ll call this createLanguage function we’ve written just now, go through these five steps, and give the client a public key that will essentially serve as the user’s login credential for this particular language. That makes this whole process we just made essentially equivalent to an account creation flow.
Reading and modifying our data
Our REST API here only takes POST requests, and only creates the language. Why do you think that is? If you pause for a moment and have a think about that, you may notice this one limitation of Fauna’s GraphQL support:
👉 Administrative operations are missing!I’ve been told that this feature will be added soon, and perhaps I will come back to this once support drops, but for now, our best option is to work with operations like database creation and permissions manipulation via FQL, Fauna’s native query language. That’s why we’ve been working in a Node.JS serverless function this whole time. However, reading, updating, and deleting data is baked right into the GraphQL spec, so we can do those things straight from the browser! We’ll get to skip our Netlify backend entirely and ping the database directly. Think about the performance gains of that! Not that our conlang manager here needed to be the fastest application ever, but given this extremely lean and direct architecture, it very well could make a play for the title.
Let’s focus in on our frontend for a moment. I’ve redirected our serverless function to /api/language a la Netlify Redirects, so I’ve stuck a client-side JavaScript function in a public file called index.js that looks like this:
const createLanguage = async ({ name, creatorName, creatorEmail }) => {
const response = await fetch(
"/api/language",
{
method: "POST",
body: JSON.stringify({ name, creatorName, creatorEmail })
}
);
localStorage.credentials = (await response.json()).key;
alert(`The key for this language is '${localStorage.credentials}' minus the quotes. Please save that in your password manager, as you won't see it again, and you'll need it to access your language from now on.`);
};
const login = async credentials => {
localStorage.credentials = credentials;
};
This index.js is loaded via <script> into index.html so that I can run whatever is in here from the DevTools Console in Chrome.
A brief note about the design pattern we’re using here: that public key we’re letting the user have access to will be stored in localStorage and used in every subsequent request. So when we create a new language, the Netlify function returns that key, and here on the client, we stuff it in localStorage and alert the user so they know to save it in their password manager. The login function I’ve made here just accepts the key and saves it to localStorage, named as such because it works as a login flow.
Before we go further, let’s go back into our main database and do a few administrative things. Upload this schema to the parent database:
type Language {
name: String!
dbName: String!
key: String!
creatorName: String!
creatorEmail: String!
}
type Query {
getLanguageByKey (key: String!): Language @index(name: "getLanguageByKey")
}
It’s pretty simple, but it defines what our Language collection looks like so that we can consume it via GraphQL, and it gives us a query we can run to get a language by our main key credential.
Once we upload that, Fauna will make us an index called getLanguageByKey. Now head over to the Security tab in your database dashboard and create a new role. In that window, you should be given the option to restrict the role to read-only and only allow it to use the index Fauna just created and the associated GraphQL query (listed as a function here). What we’re doing it giving ourselves a key that is safe to use on the client side by unauthenticated users. The only thing we want them to be able to do with this is read the Language collection via the query we created, which explicitly requires the same credential that will give them access to the child database, so they can’t skirt our protective measures here.
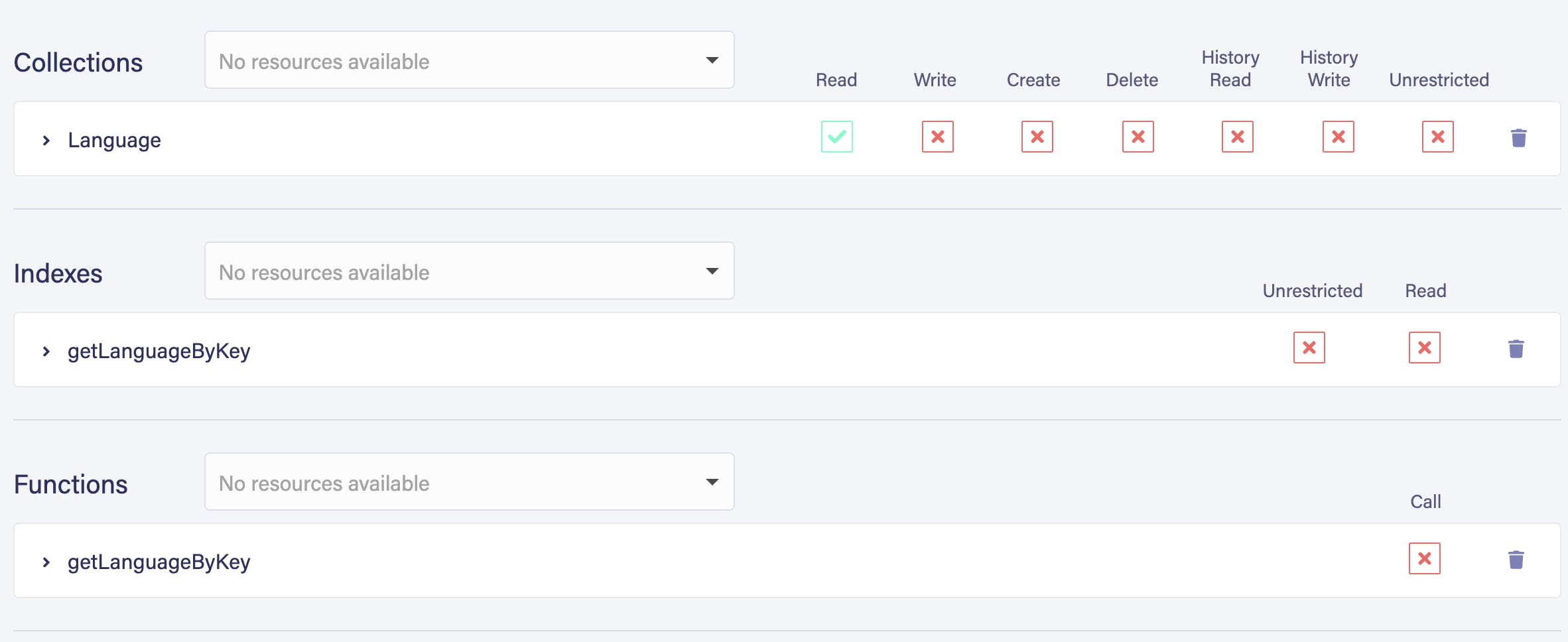
Back in Security, make an API key and attach it to this new read-only role (that’s super important, else our security shall be for naught 😉). Paste it into the top of our new client-side index.js file like this:
const FAUNA_PUBLIC_KEY = `fnAEcM3ZqGAAQFrwzSZr_heH-q0YLHXQYuQPvefk`;
const createLanguage = async ({ name, creatorName, creatorEmail }) => { /* displayed this */ };
const login = async credentials => { /* displayed this */ };
Now that we have an API with which we can safely read from the client, let’s add a few more functions for the other operations. Since we just uploaded a GraphQL schema, we’re going to use that query we created and skip our Netlify server entirely like I mentioned earlier:
const createLine = input => {
const [name, value] = Object.entries(input)[0];
return `${name}: ${JSON.stringify(value)},`;
};
const updateLine = input => {
const [name, value] = Object.entries(input)[0];
return name ? `${name}: ${JSON.stringify(value)},` : "";
};
const getObj = {
notes: () => `notes {
data {
_id
note
}
}`,
...
};
const createObj = {
note: ({note}) => `createNote (
data: {
${createLine({note})}
}
) {
_id
}`,
...
};
const updateObj = {
note: ({id, note}) => `updateNote (
${createLine({id})}
data: {
${updateLine({note})}
}
) {
_id
}`,
...
};
const deleteObj = {
note: ({id}) => `deleteNote (
${createLine({id})}
) {
_id
}`,
...
};
const getLanguage = async () => {
const parentResponse = await fetch(
"graphql.us.fauna.com/graphql",
{
method: "POST",
body: JSON.stringify({ query: `
query {
getLanguageByKey (key: "${localStorage.credentials}") {
name
creatorName
creatorEmail
}
}
` }),
headers: { "Authorization": `
Basic ${btoa(FAUNA_PUBLIC_KEY + ":")}` }
}
);
const parentResults = (await parentResponse.json()).data.getLanguageByKey;
const childResponse = await fetch(
"graphql.us.fauna.com/graphql",
{
method: "POST",
body: JSON.stringify({ query: `query {
${getObj.notes()}
${getObj.words()}
${getObj.phonemes()}
${getObj.symbols()}
${getObj.metaData()}
${getObj.phonotacticRules()}
}` }),
headers: { "Authorization": `Basic ${btoa(localStorage.credentials + ":")}` }
}
);
const childResults = (await childResponse.json()).data;
language = {
...parentResults,
metadata: childResults.metadata,
notes: childResults.notes.data,
words: childResults.words.data,
phonemes: childResults.phonemes.data,
symbols: childResults.symbols.data,
phonotacticRules: childResults.phonotacticRules.data
};
};
const mutateItem = async (mutations) => {
/*
mutations = [
[
mutation_func,
data_obj,
type, // create, update, or delete
key // of the object to mutate in language
]
]
*/
const response = await fetch(
"graphql.us.fauna.com/graphql",
{
method: "POST",
body: JSON.stringify({ query: `mutation {
${
mutations
.map(([mutation, data], i) =>
`mutation${i}: ${mutation(data)}`
)
.join("\n")
}
}` }),
headers: { "Authorization": `Bearer ${localStorage.credentials}` }
}
);
const result = await response.json();
Object.values(result.data).forEach((data, i) => {
console.log(mutations[i])
switch (mutations[i][2]) {
case "create":
language[mutations[i][3]].push({
_id: data._id,
...mutations[i][1]
});
break;
case "update":
for (let j = 0; j < language[mutations[i][3]].length; j++) {
if (language[mutations[i][3]][j]._id == data._id) {
delete mutations[i][1].id;
language[mutations[i][3]][j] = {
...language[mutations[i][3]][j],
...mutations[i][1]
}
}
}
break;
case "delete":
for (let j = 0; j < language[mutations[i][3]].length; j++) {
if (language[mutations[i][3]][j]._id == data._id) {
delete language[mutations[i][3]][j];
}
}
break;
}
});
return result;
};
Just a quick breakdown:
- The
createLineandupdateLinefunctions just take some input and turn it into a formatted GraphQL line. This is purely for convenience, so I don’t have to keep typing the same lines of GraphQL over and over. - The next four objects contain a function for each CRUD operation and for each type that we’re working with. The function just takes in the necessary data and spits out a formatted GraphQL query or mutation. Again, these are for convenience; I don’t want to write them repeatedly.
- The
getLanguagefunction pulls in the language’s data from the parentLanguagecollection and merges it with data from the child database. - The
mutateItemfunction takes in one of the query functions we defined earlier and the data used in the mutation and runs it with a fetch request.
So now, I can run something like await getLanguage() in the browser console to get everything about the language in one object. I could also run something like await mutateItem(createObj.note, {"note": "This is a note"}, "create", "notes") to add a new note to the language. It’ll use the returned document _id to update our client-side record of the language data so we don’t have to keep calling getLanguage over and over again!
Now, we can build out a super simple GUI and give the various controls onClick events like that one. I decided to spin up a quick Slinkity site and use clusterize.js to display all of this data. I won’t go into too much detail about it here since that’s not the focus of this already lengthy article, but if you’re curious, do check out the repo.
Why do we care about any of this?
Good question, hypothetical reader.
In gist, conlangs are notoriously difficult to model. And yet while posts on comparatively common and simple subjects — like building a sample REST API — can approach 4000 words, I’ve thoroughly explained how to not only model a conlang with Fauna, but build a whole application around it in the same space.
The lesson of this whole exercise is that Fauna is incredibly powerful and flexible. If you were wondering if it’s the right fit for your project, it probably is, and I probably just demonstrated some piece of your use case.
There’s more I want to do with this project though, like adding simulated language evolution with Fauna’s built-in temporality features. If you want to see that happen soon, or even just chat about Fauna or anything nerdy, reach out over on my Twitter @jadenguitarman. Or, if you’d like to learn some more about any of the features I demonstrated here or about what else Fauna can do, check out their awesome docs here.