George Githiriggithiri.hashnode.net·Feb 4, 2023Setting Up AWS Glue with Docker and ExamplesAWS Glue is a fully-managed, serverless data integration service that makes it easy to move data between data stores. In this blog, we will show you how to set up AWS Glue using Docker and provide some examples to help you get started. Step 1: Instal...13 likes·74 readsAWS
Luukcloudengineer.hashnode.net·Nov 29, 2022Re:Invent 2022 day 1 - A serverless streaming & event-driven ETL flow with Glue, redshift serverless and QuickSightTo kick-off the serverless re:Invent series, we'll start with one on AWS data engineering. It is based on re:Invent session PEX-305-R and touches upon a large set of serverless services. The main goal is to illustrate how these services can work toge...2 likes·61 readsAWS Glue
Luukcloudengineer.hashnode.net·Dec 1, 2022Re:Invent 2022 day 3 - Analyze data faster with spark notebooks in Amazon AthenaData analytics is getting more and more accessible! If you want to quickly analyze datasets, Amazon Athena has always been a very easy tool because it requires very little setup. Simply select your database and write your SQL query and you can run an...2 likes·39 readsaws athena
Martijn Sturmmartijn-sturm.hashnode.net·Apr 23, 2023Data Engineering on AWS: Best Practices OverviewThis blog post contains a listing of best-practices for data engineering on AWS. I will try to update this post regularly with new insights and best practices. Please note that this is not an exhaustive list. Am I missing an important one? Please let...How to Data Engineering on AWSdata-engineering
Martijn Sturmmartijn-sturm.hashnode.net·Apr 23, 2023Use your own Python packages in Glue jobsMany data engineering use cases require you to repeat some ETL logic on different (database) tables or event streams. It is adviced to separate the ETL workflows for those tables in separate Glue jobs for multiple reasons: Keeping your ETL runs per ...How to Data Engineering on AWSAWS Glue
Martijn Sturmmartijn-sturm.hashnode.net·Apr 23, 2023Defining ETL jobs as Infrastructure-as-CodeUsing Infrastructure-as-Code (IaC) for deployment of resources to the cloud is a no-brainer nowadays. The learning-curve at the start is a bit steeper than applying click-ops, but will pay off in te long-term. In this post I try to assist in getting ...How to Data Engineering on AWSETL
Sneh Bhattmytwocents.hashnode.net·Feb 24, 2023AWS concepts and ideas - ENABLING CONCURRENT WRITES ON S3 DATA LAKEAbstract Amazon S3 is an object store that provides scalability to store any amount of data, and customers leverage S3 to build a data lake. Being an object store, S3 has limitations when it comes to managing concurrent writes on the same data (think...36 readsAWS concepts and ideasAmazon S3
Jonathan Reisjreissup.hashnode.net·Feb 23, 2023Implementing a Data Lakehouse Architecture in AWS — Part 3 of 4Introduction In our previous article, part 2 of the series, we walked through the extraction, processing, and creation of some data mart, using the New York City taxi trip data which is publicly available to do consumption. We used some of the princi...Exploring the Data Lakehouse and Its Implementation in AWSData-lake
Jonathan Reisjreissup.hashnode.net·Feb 23, 2023Implementing a Data Lakehouse Architecture in AWS — Part 2 of 4Introduction In part 1 of this article series, we walked through how to feed a Data Lake built on top of Amazon S3, based on streaming data, using Amazon Kinesis. In part 2, we will cover all of the steps needed to build a Data Lakehouse, using trip ...Exploring the Data Lakehouse and Its Implementation in AWSData-lake
George Githiriggithiri.hashnode.net·Feb 4, 2023Setting Up AWS Glue with Docker and ExamplesAWS Glue is a fully-managed, serverless data integration service that makes it easy to move data between data stores. In this blog, we will show you how to set up AWS Glue using Docker and provide some examples to help you get started. Step 1: Instal...13 likes·74 readsAWS
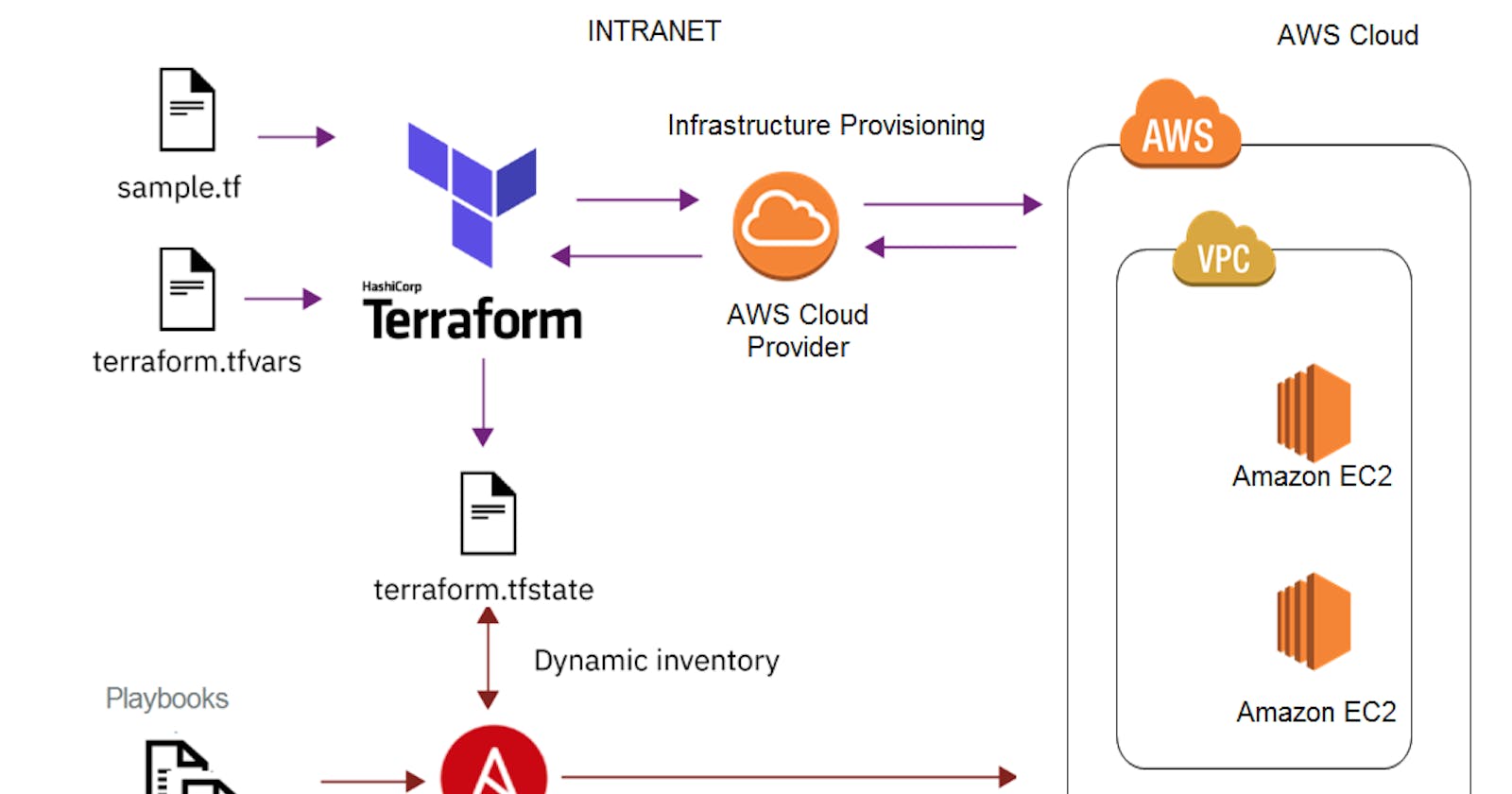
George Githiriggithiri.hashnode.net·Feb 2, 2023Deploying a Data Pipeline Model using Terraform on AWSTerraform is an open-source infrastructure as code (IAC) tool that allows you to manage and provision your infrastructure resources. In this blog, we will show you how to deploy a data pipeline model using Terraform on AWS. Step 1: Install Terraform ...149 readsAWS
Luukcloudengineer.hashnode.net·Dec 1, 2022Re:Invent 2022 day 3 - Analyze data faster with spark notebooks in Amazon AthenaData analytics is getting more and more accessible! If you want to quickly analyze datasets, Amazon Athena has always been a very easy tool because it requires very little setup. Simply select your database and write your SQL query and you can run an...2 likes·39 readsaws athena
Luukcloudengineer.hashnode.net·Nov 29, 2022Re:Invent 2022 day 1 - A serverless streaming & event-driven ETL flow with Glue, redshift serverless and QuickSightTo kick-off the serverless re:Invent series, we'll start with one on AWS data engineering. It is based on re:Invent session PEX-305-R and touches upon a large set of serverless services. The main goal is to illustrate how these services can work toge...2 likes·61 readsAWS Glue